1. 背景
LTMDB SQL 内存引擎是基于 LDP MDB 存储引擎和 OpenGuass 的自主研发的内存数据库。
1.1. 术语定义
LTMDB: 一种 SQL 计算引擎,它集成 MDB 内存数据库作为存储层,为内存数据库提供 SQL 能力,可嵌入应用程序通过 C/C++ API 访问,也可以通过 Socket 访问(后续将支持 JNI 调用)
MDB:是一款内存数据库,拥有存储、索引、事务等能力
1.2. 整体结构
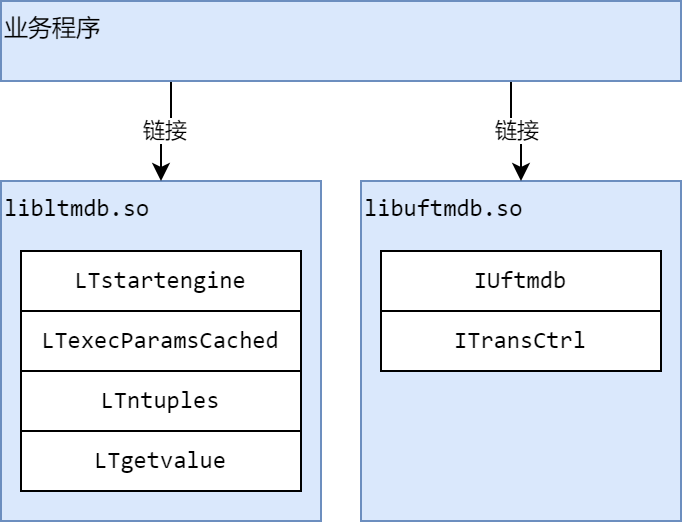
SQL 内存引擎与 MDB 内存数据库是集成使用的。
SQL 内存引擎是一个动态库,用户需要编写程序来使用 SQL 内存引擎中的功能。
SQL 内存引擎支持 C API 接入,与 Socket 接入;不过这些方式都需要用户编写程序来加载 MDB ,并启动 SQL 内存引擎。

链接时主要需要两个动态库:
2. 安装与配置
首先应获取 LTMDB 的安装包,目前需要在效能平台获取,请邮件联系 LightDB 团队,以获取安装包。
安装包解压后的目录结构为:
.
├── bin
│ ├── gaussdb
│ └── gsql
├── env_gsql.sh
├── include
│ ├── 其他头文件
│ └── sql_engine.h
├── lib
│ ├── 其他so
│ └── libsqlengine.so
├── LT_BUILD
└── share
└── postgresql
├── 其他支撑文件
└── lightdb_basedata.tar.gz
要使用 LTMDB ,可参考 example 目录,其中包含了一个使用 SQL 内存引擎 API 的示例.
example 使用前需要做一些配置:
配置
UFTMDB_HOME环境变量,指向 MDB 安装目录LTMDB_HOME指向 LTMDB 解压路径,以及对应的PATH,LD_LIBRARY_PATH
环境变量的处理方式可参考 example/run-example.sh 。
3. C API 接入方法
SQL 内存引擎提供了 C API ,相关的 API 在 安装包/include/sql_engine.h 中定义,发布包的 example 目录中包含调用方法的示例。
3.1. 接口列表
初始化类
函数名 |
用途 |
|---|---|
LTsetEngineThreadCallback |
设置引擎线程回调函数 |
LTstartengine |
启动引擎 |
LTstopengine |
停止引擎 |
LTsetTableActionCallback |
设置增删改回调函数 |
连接管理类
函数名 |
用途 |
|---|---|
LTconnectdb |
连接数据库 |
LTstatus |
获取状态 |
LTerrorMessage |
获取错误信息 |
LTfinish |
结束操作 |
执行类
函数名 |
用途 |
|---|---|
LTexec |
执行SQL命令 |
LTexecCached |
执行SQL命令(支持缓存) |
LTexecParams |
执行带参数的SQL命令 |
LTexecParamsCached |
执行带参数的SQL命令(支持缓存) |
LTprepare |
预准备SQL命令 |
LTexecPrepared |
执行预准备的SQL命令 |
LTresultStatus |
获取结果状态 |
LTresStatus |
获取结果状态 |
LTresultErrorMessage |
获取结果错误信息 |
LTresultErrorField |
获取结果错误字段(比如错误码) |
LTclear |
清除结果 |
结果获取类
函数名 |
用途 |
|---|---|
LTntuples |
获取元组数 |
LTnfields |
获取字段数 |
LTscanCount |
获取扫描次数 |
LTfname |
获取字段名称 |
LTfnumber |
获取字段编号 |
LTgetvalue |
获取字段值 |
LTgetlength |
获取字段长度 |
LTgetisnull |
检查字段是否为空 |
LTcmdTuples |
获取命令影响的元组数 |
LTgetCacheId |
获取带缓存接口的cacheId |
LTftype |
获取某列的类型,类型参考 sql_engine.h 中的宏定义 |
LTftable |
获取某列对应表的 oid |
LTftablecol |
获取某列在对应表的顺序,从1开始 |
LTftableName |
获取某列对应表的名字,小写返回 |
LTgetVersion |
获取版本信息 |
详细的 API 使用方法参考头文件 sql_engine.h 的注释。
3.2. SQL 接口使用示例
典型的 SQL 内存引擎 API 使用方式可参考以下代码结构:
#include <iostream>
#include <chrono>
#include <iomanip>
#include <unistd.h>
#include "uftmdb/Include/uftmdb.h"
#include "uftmdb/Include/admin.h"
#include "uftmdb/Include/uftmdb_lib.h"
#include "gen/simple_example_impl.h"
#include "gen/simple_example_2_impl.h"
#include "mdb_test.h"
#include "sql_engine.h"
static bool demo_normal()
{
char output[OUTPUT_MESSAGE_BUFFER_SIZE];
LTresult *res;
LtExecStatusType status;
// 2. 执行 SQL 前必须建立‘连接’
LTconn *conn = LTconnectdb(NULL);
// 3. 清空数据
printf("准备执行 DELETE 语句 清空 simple_example 与 simple_example_2 表\n");
res = LTexec(conn, "delete from simple_example");
status = LTresultStatus(res);
if (status != LTRES_COMMAND_OK)
{
fprintf(stderr, "DELETE simple_example 执行失败(%d):%s\n", status, LTerrorMessage(conn));
goto error;
}
else
{
printf("DELETE simple_example 已执行\n");
}
printf("\n");
LTclear(res);
// 4. 简单 SQL
// 4.1 INSERT
printf("1. 准备执行 INSERT 语句\n");
res = LTexec(conn, "insert into simple_example (id, int01, varchar01) values (1, 10001, 'Data01'), (2, 10002, 'Data02');");
status = LTresultStatus(res);
if (status != LTRES_COMMAND_OK)
{
fprintf(stderr, "INSERT 执行失败(%d):%s\n", status, LTerrorMessage(conn));
goto error;
}
else
{
printf("INSERT 已执行\n");
}
printf("\n");
LTclear(res);
// 4.2 UPDATE
printf("2. 准备执行 UPDATE 语句\n");
res = LTexec(conn, "update simple_example set int01 = 1000200 where id = 2");
status = LTresultStatus(res);
if (status != LTRES_COMMAND_OK)
{
fprintf(stderr, "UPDATE 执行失败(%d):%s\n", status, LTerrorMessage(conn));
goto error;
}
else
{
printf("UPDATE 已执行\n");
}
printf("\n");
LTclear(res);
// 4.3 DELETE
printf("3. 准备执行 DELETE 语句\n");
res = LTexec(conn, "delete from simple_example where id = 1");
status = LTresultStatus(res);
if (status != LTRES_COMMAND_OK)
{
fprintf(stderr, "DELETE 执行失败(%d):%s\n", status, LTerrorMessage(conn));
goto error;
}
else
{
printf("DELETE 已执行\n");
}
printf("\n");
LTclear(res);
// 4.4 SELECT ,注意查询是 LTRES_TUPLES_OK 不是 LTRES_COMMAND_OK
printf("4. 准备执行 SELECT 语句\n");
res = LTexec(conn, "select * from simple_example where id in (1, 2)");
status = LTresultStatus(res);
if (status != LTRES_TUPLES_OK)
{
fprintf(stderr, "SELECT 执行失败(%d):%s\n", status, LTerrorMessage(conn));
goto error;
}
else
{
printLTResult(res, output, OUTPUT_MESSAGE_BUFFER_SIZE);
printf("SELECT 已执行,结果:\n%s\n", output);
}
printf("\n");
LTclear(res);
// 4.5 DELETE
printf("5. 准备执行 DELETE 语句清空\n");
res = LTexec(conn, "delete from simple_example where id = 2");
status = LTresultStatus(res);
if (status != LTRES_COMMAND_OK)
{
fprintf(stderr, "DELETE 执行失败(%d):%s\n", status, LTerrorMessage(conn));
goto error;
}
else
{
printf("DELETE 已执行\n");
}
printf("\n");
LTclear(res);
// 连接回收
LTfinish(conn);
return true;
error:
LTfinish(conn);
return false;
}
int main(int argc, char *argv[])
{
char error[ERROR_MAX_LENGTH];
IUftmdb *uftmdb;
int32_t errorno;
// 初始化 UFTMDB (MDB 加载过程省略)
errorno = init_uftmdb(&uftmdb, error, ERROR_MAX_LENGTH);
if (errorno != 0) {
printf("Error init_uftmdb: %s\n", error);
return 1;
}
// 1. 开启 SQL 内存引擎,一个进程只能运行一次
LtEngineConfigs *engine_configs = LTinitEngineConfig(3);
LTsetEngineConfigBystr(engine_configs, "work_mem=64MB");
LTsetEngineConfig(engine_configs, "shared_buffers", "64MB");
// 定义端口
LTsetEngineConfigBystr(engine_configs, "port=29576");
// 设置日志路径
LTsetEngineConfig(engine_configs,"log_directory=/tmp");
// 设置日志1天自动轮换
LTsetEngineConfig(engine_configs,"log_rotation_age=1d");
// 设置自动清理1天前日志
LTsetEngineConfig(engine_configs,"lightdb_log_retention_age=1d");
LtEngineInitStatusType start_type = LTstartengine(uftmdb, "example-test-data", NULL, engine_configs);
if (start_type != LT_ENGINE_OK)
{
printf("Start engine failed! %d\n", start_type);
return 1;
}
LTreleaseEngineConfig(engine_configs);
printf("Main start\n");
// 在这里进行 sleep 可测试 socket 接入方式
// sleep(100000);
// 在 demo_normal 函数中模拟用户业务代码
demo_normal();
// 引擎终止,整个程序只能运行一次
printf("退出引擎\n");
LTstopengine();
return 0;
}
备注
更多使用方式可参考发布物中的示例代码 example/main.cpp 。
3.3. MDB 接口使用示例
若应用程序对性能有更高的要求,可直接使用内存数据库 MDB 的 API 来操作数据,以获得更高的运行效率。
要使用 MDB 接口,有以下几个主要步骤:
事先使用 C++ 语言定义表结构
初始化 MDB 实例
加载表结构
使用事务控制器访问数据
4. Java API 接入方法
本章节介绍如何在 Java 项目中使用本 JDBC 驱动进行数据库访问。
4.1. JDBC 驱动加载
目前驱动 jar 包放在发布物路径 lightdb-ltmdb/java 中。
由于本驱动基于 JNI 开发,运行前需正确配置动态库路径,否则会导致 UnsatisfiedLinkError。 请确保 LD_LIBRARY_PATH 将发布物的动态库路径正确进行设置了:
export LD_LIBRARY_PATH=/path/to/lightdb-ltmdb/lib:/path/to/uftmdb/instance/linux.x64/
其中:
/path/to/lightdb-ltmdb/lib/ 为发布物 lib 目录。
/path/to/uftmdb/instance/linux.x64/ 为 MDB 动态库路径,需要与当前 CPU 架构匹配;如果仅为了功能测试,可使用 lightdb-ltmdb/mdb 目录中的 MDB 动态库。
驱动可通过以下方式加载:
Class.forName("com.hundsun.ldp.ltmdb.LtmdbDriver");
而后可使用 JDBC URL 进行自动加载:
Connection connection = DriverManager.getConnection("jdbc:ltmdb:mem/");
本驱动的 JDBC URL 目前采用如下格式:
jdbc:ltmdb:mem/
暂未支持其他的 URL 配置项。
4.2. JDBC 注意事项
目前不支持 setBytes, setBlob 二进制接口
CREATE TABLE 建表必须在任何 DML/DQL 之前,否则会报错
4.3. MyBatis 兼容性
本驱动可支持结合 Spring Boot + Druid 连接池 + MyBatis 使用,可直接在 application.properties 中配置数据源,例如:
spring.datasource.url=jdbc:ltmdb:mem:/
spring.datasource.driver-class-name=com.hundsun.ldp.ltmdb.LtmdbDriver
mybatis.mapper-locations=classpath:mapper/*.xml
4.4. JDBC MDB 初始化方法
目前 SQL 引擎的 JDBC 驱动默认可以初始化一个单机的 MDB 实例,JDBC 仅支持连接到一个 Uftmdb 实例。 如果单机的 MDB 实例不满足您的需求,您可以在 main 函数中手动进行初始化, 然后调用 initEngine 方法,将您初始化的 IUftmdb* 指针传入到第二个参数:
// 假设这里是您自己通过 JNI 封装的初始化逻辑
long lpIUftmdb = initMyUftmdb();
// 调用初始引擎
Properties p = new Properties()
p.setProperty("ltmdb.datadir", "/home/lightdb/.cache/tmp-sqlengine"); // SQL 引擎运行临时目录,需要指定一个非 tmpfs 的路径
p.setProperty("ltmdb.port", "5535"); // SQL 引擎端口,默认 4323
p.setProperty("ltmdb.sqlenginehome", "/path/to/lightdb-ltmdb"); // SQL 引擎发布物路径
com.hundsun.ldp.ltmdb.LtmdbDriver.initEngine(p, lpIUftmdb);
其中 Properties 参数的各项参数为:
key |
说明 |
|---|---|
ltmdb.datadir |
SQL 引擎运行临时目录,默认为当前目录的 tmp ;需要指定一个非 tmpfs 的路径 |
ltmdb.port |
SQL 引擎 Socket 接口端口,目前需要指定,默认为 4323 |
ltmdb.sqlenginehome |
指向 SQL 引擎 发布物路径,默认为当前目录的 lightdb-ltmdb 目录,请确保操作系统与 CPU 平台匹配 |
Properties 中的各项参数均可以通过 jvm 的 -D 参数设置,如 -Dltmdb.sqlenginehome=/home/test/lightdb-ltmdb 。
4.5. JDBC CREATE TABLE 建表说明
目前 SQL 引擎支持建表,但必须在任何 DML/DQL 发生前进行。
所以,对于 Spring Boot 应用,推荐在 main 函数中实现把表建立起来,避免连接池加载时自动开启了 MDB 事务导致后续建表失败,例如:
@SpringBootApplication
public static void main(String[] args) {
try (Connection conn = DriverManager.getConnection("jdbc:ltmdb:mem/");
Statement stmt = conn.createStatement();) {
stmt.execute("CREATE TABLE users (\n" +
" id NUMBER PRIMARY KEY,\n" +
" varchar2_column VARCHAR2(255),\n" +
" char_column CHAR(1),\n" +
" number_column NUMBER,\n" +
" date_column number,\n" +
" timestamp_column number,\n" +
" boolean_column NUMBER(1)\n" +
");\n");
stmt.execute("CREATE TABLE orders (\n" +
" order_id NUMBER PRIMARY KEY,\n" +
" user_id NUMBER NOT NULL,\n" +
" order_amount NUMBER(10, 2) NOT NULL,\n" +
" order_date BIGINT\n" +
")");
stmt.execute("CREATE TABLE mybatis_demo_table (\n" +
" user_id NUMBER(10) PRIMARY KEY,\n" +
" name VARCHAR2(100),\n" +
" age NUMBER(10),\n" +
" birth_date number,\n" +
" salary DECIMAL(10,2),\n" +
" is_active CHAR(1),\n" +
" description CLOB,\n" +
" float_col FLOAT,\n" +
" binary_float_col BINARY_FLOAT,\n" +
" binary_double_col BINARY_DOUBLE,\n" +
" long_col NUMBER(19),\n" +
" timestamp_col number\n" +
")");
} catch (SQLException e) {
throw new RuntimeException("建表失败!", e);
}
SpringApplication.run(DemoApplication.class, args);
}
表结构中必须有一个主键约束。
4.6. JDBC 代码示例
以下是一段使用 JDBC 操作数据的 Demo 代码:
import java.io.IOException;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.time.LocalDateTime;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.Executor;
import java.util.concurrent.TimeUnit;
public class UftmdbJavaDemo {
// 数据库连接信息
private static final String JDBC_URL = "jdbc:ltmdb:mem/";
public static void main(String[] args) {
boolean failed = false;
System.out.println("环境变量 PATH: " + System.getenv("PATH"));
System.out.println("环境变量 LD_LIBRARY_PATH: " + System.getenv("LD_LIBRARY_PATH"));
System.out.println("环境变量 MDBHOME: " + System.getenv("MDBHOME"));
System.out.println("环境变量 LDP20_SOURCE_ROOT: " + System.getenv("LDP20_SOURCE_ROOT"));
System.out.println("环境变量 HSLDP_HOME: " + System.getenv("HSLDP_HOME"));
Class.forName("com.hundsun.ldp.ltmdb.LtmdbDriver");
try (Connection conn = DriverManager.getConnection(JDBC_URL);
Statement stmt = conn.createStatement()) {
stmt.execute("CREATE TABLE users (\n" +
" user_id NUMBER PRIMARY KEY,\n" +
" username VARCHAR2(50) NOT NULL,\n" +
" age bigint NOT NULL,\n" +
" email VARCHAR2(100) NOT NULL,\n" +
" created_at BIGINT\n" +
");");
System.out.println("Table 'users' created successfully.");
stmt.execute("CREATE TABLE orders (\n" +
" order_id NUMBER PRIMARY KEY,\n" +
" user_id NUMBER NOT NULL,\n" +
" order_amount NUMBER(10, 2) NOT NULL,\n" +
" order_date BIGINT\n" +
");");
System.out.println("Table 'orders' created successfully.");
stmt.execute("CREATE TABLE mybatis_demo_table (\n" +
" id NUMBER(10) PRIMARY KEY,\n" +
" name VARCHAR2(100),\n" +
" age NUMBER(3),\n" +
" birth_date number,\n" +
" salary DECIMAL(10, 2),\n" +
" is_active CHAR(1),\n" +
" description CLOB,\n" +
" float_col FLOAT,\n" +
" binary_float_col BINARY_FLOAT,\n" +
" binary_double_col BINARY_DOUBLE,\n" +
" long_col NUMBER(19),\n" +
" timestamp_col number\n" +
");");
System.out.println("Table 'mybatis_demo_table' created successfully.");
// 插入数据
stmt.executeUpdate("INSERT INTO users(user_id, username, age) VALUES (1, 'Alice', 25)");
stmt.executeUpdate("INSERT INTO users(user_id, username, age) VALUES (2, 'Bob', 30)");
stmt.executeUpdate("INSERT INTO users(user_id, username, age) VALUES (3, 'Charlie', 28)");
System.out.println("Inserted records into 'users'.");
// 查询数据
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
System.out.println("User records:");
printResultSet(rs);
// 更新数据
stmt.executeUpdate("UPDATE users SET age = 35 WHERE user_id = 2");
System.out.println("Updated Bob's age.");
// 删除数据
stmt.executeUpdate("DELETE FROM users WHERE user_id = 1");
System.out.println("Deleted Alice's record.");
// 查询数据
rs = stmt.executeQuery("SELECT * FROM users");
System.out.println("User records after update and delete:");
printResultSet(rs);
} catch (SQLException e) {
throw new RuntimeException("Demo 运行异常", e);
}
}
// 结果集打印函数
private static void printResultSet(ResultSet rs) throws SQLException {
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
// 打印表头
for (int i = 1; i <= columnCount; i++) {
System.out.print(metaData.getColumnName(i) + "\t");
}
System.out.println();
// 打印行数据
while (rs.next()) {
for (int i = 1; i <= columnCount; i++) {
System.out.print(rs.getString(i) + "\t");
}
System.out.println();
}
System.out.println("----------------------------------");
}
}
4.7. JDBC 接口支持情况
本章节列出了 JDBC 接口的支持情况,未提及的接口均不支持。
4.7.1. Driver 接口
接口 |
支持情况 |
|---|---|
DriverManager 加载 Class.forName |
已支持 |
DriverManager.getConnection 传入 jdbc:ltmdb:mem URL |
已支持,可创建 LtmdbConnection 连接 |
手动初始化引擎(清空 /dev/shm 后传入 IUftmdb* 指针) |
已支持 |
手动初始化引擎(清空 /dev/shm,传入 NULL) |
已支持,自动加载内存版数据库 |
4.7.2. Connection 接口
接口 |
支持情况 |
|---|---|
createStatement |
已支持 |
prepareStatement |
已支持 |
setAutoCommit(boolean autoCommit) |
已支持,默认 true |
commit / rollback |
已支持 |
close() |
已支持 |
setReadOnly(true) |
已支持,INSERT 预计抛异常 |
getReadOnly() |
已支持 |
4.7.3. Statement 接口
接口 |
支持情况 |
|---|---|
executeQuery |
已支持 |
executeUpdate |
已支持 |
execute |
已支持 |
getUpdateCount / getResultSet |
已支持 |
close() |
已支持 |
addBatch / executeBatch |
已支持 |
clearBatch |
已支持 |
4.7.4. PreparedStatement 接口
接口 |
支持情况 |
|---|---|
executeQuery |
已支持 |
executeUpdate |
已支持 |
execute |
已支持 |
addBatch / executeBatch |
已支持 |
clearBatch |
已支持 |
setByte |
已支持 |
setShort |
已支持 |
setInt |
已支持 |
setLong |
已支持 |
setFloat |
已支持 |
setDouble |
已支持 |
setBigDecimal |
已支持 |
setString |
已支持 |
setBytes |
不支持 |
setDate |
已支持,按照 unix epoch 格式存储 |
setTime |
已支持,按照 HHmmss 格式存储 |
setTimestamp |
已支持,按照 unix epoch 格式存储 |
setObject |
仅支持 Byte, Short, Integer, Long, Float, Double, BigDecimal, String, Date, Time, Timestamp,其他类型预计抛出异常 |
setNull |
已支持 |
4.7.5. ResultSet 接口
接口 |
支持情况 |
|---|---|
getString |
已支持,任何类型的数据都可以用 getString 获取 |
getBoolean |
已支持,值为 1 或小写的 "true" 时返回 true,否则返回 false |
getByte |
已支持,值为字符串时返回字符串中第一个字符的字节表示 |
getShort |
已支持,值为符合区间的数字时返回 short 类型数字 |
getInt |
已支持,值为符合区间的数字时返回 int 类型数字 |
getLong |
已支持,值为符合区间的数字时返回 long 类型数字 |
getFloat |
已支持,值为符合区间的数字时返回 float 类型数字 |
getDouble |
已支持,值为符合区间的数字时返回 double 类型数字 |
getBigDecimal |
已支持,值为数字时返回 BigDecimal 对象 |
getBytes |
已支持,按照 String 的 UTF-8 编码字节返回 |
getDate |
已支持,按照 unix epoch 格式解析实际值返回 |
getTime |
已支持,按照 HHmmss 格式解析实际值返回 |
getTimestamp |
已支持,按照 unix epoch 格式解析实际值返回 |
getAsciiStream |
已支持,按照 String 的 UTF-8 编码字节返回实际值 |
getUnicodeStream |
已支持,按照 String 的 UTF-8 编码字节返回实际值 |
getBinaryStream |
已支持,按照 String 的 UTF-8 编码字节返回实际值 |
getObject(index) |
已支持,按照 SQL 引擎返回类型,对应到 Java 类型返回对象 |
getObject(index, Class) |
已支持,按照传入类型解析实际值返回 |
游标类方法 (first, last, move, updateXxx) |
不支持,调用预计抛出异常 |
Blob 相关接口 |
不支持,调用预计抛出异常 |
5. Socket 接入方法
当成功调用 LTstartengine 之后,SQL 内存引擎会开启主线程,开始监听 Socket ,默认端口为 5432。
当然,如果您的主线程运行结束,或调用了 LTstopengine 之后,Socket 就会停止监听。
使用 Socket 连接的方法主要有:
使用 gsql 工具连接
使用 OpenGauss 提供的 jdbc 连接
使用客户端工具(如 navicat, dbeaver 等)
备注
可通过 LTstartengine 传入配置项 "port=端口号" 来修改监听端口号,同时 gsql 或 jdbc 连接时也要对应修改。
使用 TCP 连接,初始用户将无法连接。创建用户后,你需要决定该用户可以访问哪些数据库或表以及具有什么样的操作权限。
5.1. gsql 连接
SQL 内存引擎的发布包中带了 gsql 工具,可使用 gsql 工具连接 SQL 内存引擎的 Socket 接口。
使用前需要先配置环境变量,包括 LTMDB_HOME, PATH, LD_LIBRARY_PATH (可使用发布包的 env_gsql.sh)。
典型连接方法: gsql -r postgres -U ltmdb -p 5432 (可使用 -h 指定ip连接),成功连接后可输入 \h 查看 gsql 使用方法,或参考更详细的
网上文档。
通过 gsql 可以查看 SQL 的执行计划:
ltmdb=# prepare x_local(varchar) as select * from simple_example_local where varchar01 = $1;
PREPARE
Time: 0.624 ms
ltmdb=# explain analyze execute x_local('a');
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on simple_example_local (cost=0.00..3.26 rows=1 width=2280) (Actual time: never executed)
Filter: ((varchar01)::text = ($1)::text)
Total runtime: 0.088 ms
(3 rows)
6. 常用参数配置
参数配置可通过 LTstartengine 接口传入,以覆盖默认配置;具体用法可参照 example/main.cpp 中的写法。
配置项 |
默认值 |
描述 |
|---|---|---|
listen_addresses |
|
监听地址,可使用 |
port |
5432 |
监听端口号 |
max_connections |
200 |
Socket 最大连接数 |
session_timeout |
10min |
会话超时时间,可设置 0 使 session 不过期 |
max_process_memory |
12GB |
最大内存使用量 |
shared_buffers |
1024MB |
System V 共享内存大小,会缓存执行计划等信息 |
mdb_update_limit |
10000 |
控制 MDB 在一次事务中最多可以执行的 update 的次数,超过则会报错 |
log_directory |
pg_log |
日志文件存放路径,可以是绝对路径,也可以是相对于DATA目录(LTstartengine函数指定)的路径 |
log_truncate_on_rotation |
off |
如果参数是on,将截断(覆盖)任何同名的现有日志文件。如果参数为off,追加到任何同名的现有日志文件 |
log_rotation_age |
1d |
多久之后日志文件将自动轮换。0代表禁用。如果指定此值时没有单位,则将其视为分钟 |
lightdb_log_retention_age |
1d |
此参数确定保留日志文件的最长时间,切换日志文件时将清理超过此时间的日志, 0代表禁用。如果指定此值时没有单位,则将其视为分钟 |
mdb_allow_question_sign_params |
off |
是否允许问号作为绑定变量占位符,默认为 off ;开启后可使用 ? 作为占位符,如 LTprepare(conn, "p1", "insert into simple_example (id, int01) values (?, ?)", 2, NULL); |
7. SQL 参考
本章列举 SQL 引擎支持的 SQL 特性情况。
7.1. SQL 特性参考
在以下清单中的 SQL 特性是明确支持的,其他未提及的特性也可能支持,但不建议使用,可能导致非预期的行为!
主项 |
分项 |
子项 |
子元素项 |
描述 |
是否支持 |
支持说明 |
|---|---|---|---|---|---|---|
DDL |
CREATE |
索引创建(CREATE INDEX) |
在临时表上创建索引 |
普通的 CREATE INDEX 语句,在临时表创建索引 |
是 |
|
UNIQUE 子句 |
创建唯一索引 |
是 |
||||
临时表创建(CREATE TEMPORARY TABLE) |
create temporary table |
会话临时表(会话退出后就消失了) |
是 |
|||
视图创建 CREATE VIEW |
create view |
普通视图的创建 |
是 |
|||
create or replace view |
普通视图的创建或替换 |
是 |
||||
ALTER |
ALTER INDEX |
alter index rebuild |
兼容ORACLE alter index rebuild |
是 |
对临时表有效 |
|
表更改(ALTER TABLE) |
alter table xxx drop constraint xxx drop index |
在Oracle中,当在alter table时,可以将同一列的索引和约束同时进行删除 |
是 |
对临时表有效 |
||
alter table add constraint |
支持alter table add constraint语法 |
是 |
对临时表有效 |
|||
指定列默认值、NOT NULL等标准SQL属性 |
Oracle兼容alter modify修改字段类型, 默认值, 非空 |
是 |
对临时表有效 |
|||
DROP |
DROP INDEX |
DROP INDEX |
索引删除 |
是 |
||
函数删除(DROP FUNCTION) |
是 |
|||||
过程删除(DROP PROCEDURE) |
是 |
|||||
临时表删除(DROP TEMPORARY TABLE) |
是 |
|||||
视图删除(DROP VIEW) |
是 |
|||||
TRUNCATE |
表清空(TRUNCATE TABLE) |
TRUNCATE |
临时表 |
部分支持 |
仅对临时表有效,对 mdb 表无效 |
|
DML |
SELECT |
子查询 |
select * from (select ...) [[as] t] |
子查询as别名可选 |
是 |
|
字段、对象名、别名为关键字 |
astable等关键字作为字段别名 |
as支持作为别名,select as as from t; |
是 |
|||
astable等关键字作为表名 |
是 |
|||||
astable等关键字作为表别名 |
是 |
|||||
select for update |
select for update |
支持 select for update 进行行锁 |
是 |
|||
分页查询 |
12c之后fetch写法 |
[OFFSET n] FETCH NEXT m ROWS ONLY |
是 |
|||
11g之前的rownum写法 |
rownum > n and rownum < m |
是 |
||||
WITH查询语句(WITH AS CLAUSE) |
普通with |
是 |
||||
CONNECT BY |
connect by |
支持 connect by 语法,level、prior关键字 |
是 |
|||
level |
connect by支持绑定变量 |
是 |
||||
prior |
oracle树形查询 |
是 |
||||
distinct |
支持distinct … conncet by level用法 |
是 |
||||
where level op length(col) |
oracle connect by是用于解决层次查询的高效特性,能够提供比分析函数、PL/SQL更高效、更高性能 |
是 |
||||
集合操作 |
UNION和UNION ALL |
是 |
||||
MINUS |
是 |
|||||
INTERSECT |
是 |
|||||
外关联 |
外关联 |
Oracle外关联支持(+) |
是 |
|||
LEFT JOIN |
左外关联 |
是 |
||||
RIGHT JOIN |
右外关联 |
是 |
||||
GROUP BY |
表达式 |
是 |
||||
CUBE/GROUPING/GROUPING SETS/ROLLUP |
是 |
|||||
列别名 |
是 |
|||||
数字 |
是 |
|||||
ORDER BY |
NULLS LAST/NULLS FIRST |
是 |
||||
列别名 |
是 |
|||||
支持聚合函数与order by结合运算 |
是 |
|||||
数字 |
是 |
|||||
INSERT |
insert into t values(a,b,c,default) |
普通 INSERT 带 DEFAULT |
DEFAULT字面值 |
是 |
||
目标表带别名 |
支持insert into t(a,b,c) v values(...) |
INSERT INTO 表带别名 |
部分支持 |
必须带 AS |
||
UPDATE |
普通更新语句(UPDATE CLAUSE) |
update t t1 set t1.v = 'abc' |
update单表支持别名 |
是 |
||
DELETE |
删除语句(DELETE CLAUSE) |
delete tableName |
oracle支持delete不带from关键字 |
是 |
||
MERGE |
MERGE更新语句(MERGE MATCHED UPDATE) |
普通matched |
计划支持 |
|||
带where条件matched |
计划支持 |
|||||
MERGE插入语句(MERGE NOT MATCHED INSERT) |
merge into insert语句分支(a.column)支持insert中用表别名 |
计划支持 |
||||
merge结合with cte |
"with xx as merge into t using (select * from xx)" |
支持merge into with cte 语法 |
计划支持 |
|||
命令查看执行计划(EXPLAIN) |
命令查看执行计划(EXPLAIN) |
普通 EXPLAIN 语句 |
EXPLAIN query |
是 |
||
支持递归语句执行计划查看 |
支持connect by递归语句执行计划显示正确 |
是 |
||||
优化器提示(hint_plan) |
扫描方法 |
INDEX |
强制对表进行索引扫描。如果指定了,则限制为指定的索引 |
是 |
||
PL/SQL |
PL/SQL对象创建、删除、管理 |
函数创建 CREATE FUNCTION |
create function |
创建oracle函数 |
是 |
|
function 名称或者出入参带有关键字支持 |
比如参数名index,level等 |
是 |
||||
支持in、out和in out三种参数模式 |
是 |
|||||
支持参数超过100个 |
是 |
|||||
过程创建 CREATE PROCEDURE |
支持OR REPLACE重建存储过程 |
是 |
||||
支持参数超过100个 |
是 |
|||||
存储过程 |
存储过程 |
PL/SQL 存储过程支持 |
Oracle 格式的存储过程 |
部分支持 |
部分支持 PL/SQL 的特性,完整支持 PL/pgSQL 特性 |
|
函数 |
函数 |
PL/SQL 函数支持 |
Oracle 格式的函数 |
部分支持 |
部分支持 PL/SQL 的特性,完整支持 PL/pgSQL 特性 |
|
操作符 |
操作符(oracle) |
通用运算符 |
通用运算符 |
!= * + - / < <= < = > >= ! AND LIKE OR |
是 |
|
NULL 判断运算符 |
IS NULL, IS NOT NULL |
部分支持 |
可在临时表使用 |
|||
mod运算符 |
支持mod取余运算符 |
是 |
||||
|| |
双竖线运算符兼容,主要是字符串和非字符串的拼接兼容,非字符串和非字符串的兼容 |
是 |
||||
字符集 |
默认排序规则 |
安装时指定服务端字符集 |
计划支持 |
|||
字符集 |
字符集支持 |
GBK和GB18030-2022 |
支持客户端和服务端选择GBK/GB18030,能够正确的相互转换 |
部分支持 |
||
数据类型兼容 |
字符类型 |
可变长度字符类型(varchar2) |
varchar2 |
varchar2类型采用varchar实现 |
是 |
|
varchar类型兼容 |
varchar类型兼容 |
是 |
||||
字符类型(char) |
字符类型 |
char类型字符长度兼容 |
部分支持 |
可在临时表使用 |
||
nchar |
支持nchar类型 |
部分支持 |
可在临时表使用 |
|||
nvarchar2 |
支持nvarchar2类型 |
部分支持 |
可在临时表使用 |
|||
单字节和多字节字符数据(clob) |
部分支持 |
可在临时表使用 |
||||
二进制大对象(blob) |
oracle blob |
对oracle blob对null特殊处理如empty_blob的兼容 |
部分支持 |
可在临时表使用 |
||
日期类型 |
日期和时间(date) |
Oracle模式下date类型做减法 |
结果支持numeric类型,oracle为number类型 |
部分支持 |
可在临时表使用 |
|
数字类型 |
数值类型(number) |
number和boolean类型比较 |
支持number和boolean类型比较 |
是 |
||
32位浮点数(binary_float) |
binary_float类型 |
兼容binary_float |
是 |
|||
64位浮点数(binary_double) |
binary_double类型 |
兼容binary_double |
是 |
|||
整数类型(int) |
int类型,Oracle 底层依旧是 number |
支持 int 类型 |
是 |
由于 number 与 int4 存在转换函数,行为方面兼容 |
||
表达式兼容 |
系统参数 |
nls_timestamp_format |
指定时间戳的默认格式 |
是 |
||
表达式兼容 |
null与空兼容 |
Oracle is null/is not null语义兼容,含各种||拼接 |
仅限Oracle模式,pg&mysql不受影响 |
部分支持 |
临时表的行为与 Oracle 一致,MDB 表不会有 NULL 字段 |
|
case when then |
case 表达式 |
case 匹配表达式 |
是 |
|||
rownum |
功能支持 |
实现rownum |
是 |
|||
支持DML |
rownum及limit支持update |
是 |
||||
执行计划 |
rownum的COUNT STOPKEY实现 |
是 |
||||
标识符默认惯例兼容 |
聚合函数不带别名兼容 |
"select max(id) from t; max ----- " |
聚合函数不带别名时,返回聚合函数名,不带括号 |
是 |
||
系统函数 |
标量函数 |
oracle 条件函数 |
decode函数 |
decode函数兼容 |
是 |
|
least函数 |
least函数兼容,求最小值。忽略NULL值 |
是 |
||||
greatest函数 |
greatest函数兼容,求最大值。忽略NULL值 |
是 |
||||
oracle 字符串函数 |
rawtohex函数 |
rawtohex 转 HEX 字符串 |
是 |
|||
to_clob函数 |
实现to_clob函数将数据从文本字符串类型转换为 CLOB 类型,从而实现与 Oracle 数据库的兼容性 |
是 |
||||
substr |
兼容oracle字符串截取函数 |
是 |
||||
hs_substr |
当起始位置小于等于0时,返回NULL,其他参数和substr一致 |
是 |
||||
leftb |
左边取n个字节 |
是 |
||||
rightb |
从右边取n个字节 |
是 |
||||
bit_and, bit_or函数 |
兼容oracle位计算函数 |
是 |
||||
to_char |
兼容oracle转换为字符类型的函数 |
是 |
||||
oracle其他函数 |
ADD_MONTHS |
是 |
||||
Trim |
是 |
|||||
abs |
是 |
|||||
instr |
是 |
|||||
length |
是 |
|||||
lpad |
是 |
|||||
ltrim |
是 |
|||||
nvl |
nvl函数支持传入带类型的null,发生错误时返回正确合适的错误码 |
部分支持 |
MDB 表中不存在 NULL |
|||
replace |
是 |
|||||
round |
是 |
|||||
rpad |
是 |
|||||
sign |
是 |
|||||
substr |
是 |
|||||
substrb |
是 |
|||||
to_char |
是 |
|||||
to_date |
是 |
|||||
to_number |
是 |
|||||
to_int64 |
将字符串转成64位有符号整数 |
是 |
||||
trim |
是 |
|||||
trunc |
是 |
|||||
oracle 数学函数 |
ceil |
ceil函数兼容 |
是 |
|||
oracle 日期时间函数 |
to_date语法兼容 |
将日期格式转成double类型,可使用uftmdbdatetochar转字符串 |
是 |
|||
to_char语法兼容 |
to_char支持格式'HH24MiSS' |
是 |
||||
to_timestamp语法兼容 |
日期格式兼容oracle的to_timestamp格式码 |
是 |
||||
uftmdbdatetochar |
将double类型表示的日期格式化输出 |
是 |
||||
sysdate语义和存储兼容 |
支持 sysdate 函数 |
是 |
||||
非标量函数 |
分析函数 |
nth_value |
返回分组中第n个值 |
是 |
||
聚合函数 |
count |
统计记录数 |
是 |
|||
max |
最大值 |
是 |
||||
min |
最小值 |
是 |
||||
sum |
求和 |
是 |
||||
listagg |
listagg函数兼容 |
是 |
||||
listagg支持分析函数 |
是 |
7.2. 特殊数据类型行为
由于 MDB 内存数据库的数据类型与 SQL 标准类型有一定出入,所以在此节中对一些特殊情况做了说明。
场景 |
OpenGauss 行为 |
SQL 内存引擎实际行为 |
|---|---|---|
列类型 int32 ,使用 int64 做插入 |
ERROR: integer out of range |
ERROR: integer out of range |
列类型 int32 ,使用 int64 做 where 匹配,这个 64 位整数截断后两者应相等 |
无数据 |
无数据 |
列类型 int32 ,与 int64 值做运算 |
结果类型为 int8 |
结果类型为 int8 |
列类型 int32 ,与 double precision 值做运算 |
结果为 numeric 类型 |
结果为 numeric 类型 |
列类型 int32 ,用 int32 相加 |
若溢出则报错 |
若溢出则报错 |
列类型 int64 ,使用 int32 做插入 |
正常插入 |
正常插入 |
列类型 int64 ,使用 int32 做 where 匹配,这个 64 位整数截断后两者应相等 |
无数据 |
无数据 |
列类型 int64 ,与 int32 值做运算 |
若溢出则报错 |
若溢出则报错 |
列类型 int64 ,与 double precision 值做运算 |
结果为 numeric 类型 |
结果为 numeric 类型 |
列类型 double ,做索引,使用标量小数做匹配 |
不丢精度,正常匹配 |
精度低,但可以匹配 |
列类型 double ,做索引,使用整数做匹配 |
不丢精度,正常匹配 |
精度低,但可以匹配 |
列类型 double ,做索引,使用 text 匹配 |
不丢精度,正常匹配 |
精度低,但可以匹配 |
列类型 double ,使用标量小数做 insert |
不丢精度 |
精度有丢失 |
列类型 char[] ,存储空串 |
视为 NULL |
一种特殊的空串 |
列类型 char[] ,insert 时不指定任何内容 |
默认 NULL |
一种特殊的空串 |
列类型 char[] ,无内容时使用 IS NULL 匹配 |
正常匹配 |
无法匹配 |
列类型 char[] ,无内容时使用 IS NOT NULL 匹配 |
正常匹配 |
全部满足 |
列类型 int32 ,使用 int32 做除法运算(1/3) |
0.333333 |
0.333333 |
8. 运维管理
本章包含一些常用的问题排查手段。
8.1. 排查问题会话
可通过 pg_stat_activity 视图来寻找问题会话。
典型查询:
SELECT datid, pid, application_name, state, query FROM pg_stat_activity;
datid | pid | application_name | state | query
-------+-----------------+------------------------+--------+--------------------------------------------------------------------------
15663 | 140734724306688 | gsql | active | SELECT datid, pid, application_name, state, query FROM pg_stat_activity;
15663 | 140735028393728 | WLMArbiter | idle |
15663 | 140735103891200 | workload | active | WLM fetch collect info from data nodes
15663 | 140735227098880 | Asp | active |
15663 | 140735206651648 | statement flush thread | idle |
15663 | 140735077611264 | WorkloadMonitor | idle |
15663 | 140735351355136 | ApplyLauncher | idle |
15663 | 140735256983296 | PercentileJob | active |
15663 | 140735304169216 | TxnSnapCapturer | idle |
15663 | 140735279527680 | CfsShrinker | idle |
15663 | 140737353930240 | ltapi | active | select pg_sleep(12343342)
15663 | 140735433135872 | JobScheduler | active |
application_name 显示为 ltapi 的,就是通过 C API 接入使用的会话。
若发现某个语句长时间执行,可通过 pg_terminate_backend(pid) 将会话终止,或通过
pg_cancel_backend(pid) 终止当前语句的执行,而不是终止整个会话。
为了避免用户线程被停止,在 C API 场景, pg_terminate_backend 无法终止整个会话,只尝试终止当前语句的执行,实际作用等同于
pg_cancel_backend(pid) 。
8.2. 查询表访问相关的统计信息
可通过 pg_stat_fdw_tables 视图来寻找表的访问相关的统计信息。
典型查询:
SELECT
relname AS table_name,
seq_scan AS sequential_scans, -- 顺序扫描次数
idx_scan AS index_scans, -- 索引扫描次数
seq_scan + idx_scan AS total_scans, -- 总扫描次数
n_tup_ins AS rows_inserted, -- 插入行数
n_tup_upd AS rows_updated, -- 更新行数
n_tup_del AS rows_deleted -- 删除行数
FROM
pg_stat_fdw_tables
ORDER BY
total_scans DESC
LIMIT 10; -- 显示前10个使用频繁的表
table_name | sequential_scans | index_scans | total_scans | rows_inserted | rows_updated | rows_deleted
------------------+------------------+-------------+-------------+---------------+--------------+--------------
simple_example | 0 | 0 | 0 | 0 | 0 | 0
simple_example_2 | 0 | 0 | 0 | 0 | 0 | 0
ta | 0 | 0 | 0 | 0 | 0 | 0
tvar | 0 | 0 | 0 | 0 | 0 | 0
tb | 0 | 0 | 0 | 0 | 0 | 0
(5 rows)
用于显示前10个使用频繁的表。
pg_stat_fdw_tables 视图包含所有用户表的统计信息。可以查询扫描次数等指标。
8.3. 慢 SQL 排查
慢SQL能根据用户提供的执行时间阈值( log_min_duration_statement ),记录所有超过阈值的执行完毕的作业信息。
之后用户可以通过系统表 statement_history 查询慢 SQL 信息。
查询结果例子:
ltmdb=# \x
ltmdb=# select * from statement_history;
-[ RECORD 1 ]--------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
db_name | postgres
schema_name | "$user",public
origin_node | 0
user_name | ltmdb
application_name | ltapi
client_addr |
client_port |
unique_query_id | 2183605531
debug_query_id | 281474976710665
query | select * from simple_example where id in (?, ?)
start_time | 2024-05-29 19:50:29.430159+08
finish_time | 2024-05-29 19:50:29.431996+08
slow_sql_threshold | 1000
transaction_id | 0
thread_id | 140737353930240
session_id | 140737353930240
n_soft_parse | 0
n_hard_parse | 1
query_plan |
n_returned_rows | 1
n_tuples_fetched | 142
n_tuples_returned | 71
n_tuples_inserted | 0
n_tuples_updated | 0
n_tuples_deleted | 0
n_blocks_fetched | 92
n_blocks_hit | 82
db_time | 1837
cpu_time | 1832
execution_time | 171
parse_time | 34
plan_time | 1268
rewrite_time | 4
pl_execution_time | 0
pl_compilation_time | 0
data_io_time | 56
net_send_info | {"time":74, "n_calls":4, "size":288}
net_recv_info | {"time":0, "n_calls":0, "size":0}
net_stream_send_info | {"time":0, "n_calls":0, "size":0}
net_stream_recv_info | {"time":0, "n_calls":0, "size":0}
lock_count | 68
lock_time | 0
lock_wait_count | 0
lock_wait_time | 0
lock_max_count | 5
lwlock_count | 0
lwlock_wait_count | 0
lwlock_time | 0
lwlock_wait_time | 0
details | \x6100000002415700000003000000011300427566486173685461626c65536561726368005c000000000000000112005374726174656779476574427566666572000a00000000000000010d004461746146696c6552656164003800000000000000
is_slow_sql | t
trace_id |
advise |
这其中 details 字段是二进制的,其中包含一些慢 SQL 的详细信息(对于 MDB 场景用途较小),需要使用
pg_catalog.statement_detail_decode(details, 'plaintext', true) 来查看,效果如下:
ltmdb=# \x
ltmdb=# select query, pg_catalog.statement_detail_decode(details, 'plaintext', true) from statement_history;
-[ RECORD 1 ]-----------+----------------------------------------------------------------------------------------------------------------------------------------
query | select * from simple_example where id in (?, ?)
statement_detail_decode | ---------------Wait Events Area---------------
| '1' IO_EVENT BufHashTableSearch 92 (us)
| '2' IO_EVENT DataFileRead 83 (us)
| '3' IO_EVENT StrategyGetBuffer 11 (us)
-[ RECORD 2 ]-----------+----------------------------------------------------------------------------------------------------------------------------------------
query | delete from simple_example where id = ?
statement_detail_decode | ---------------Wait Events Area---------------
| '1' IO_EVENT BufHashTableSearch 2 (us)
8.4. 内存使用信息查看
可通过 SQL 查询以下视图来查看当前 SQL 引擎已使用的内存。
8.4.1. GS_TOTAL_MEMORY_DETAIL
GS_TOTAL_MEMORY_DETAIL 视图统计当前 SQL 引擎使用内存的信息,单位为MB。
要知道 SQL 引擎当前使用了多少内存,只需要关注 dynamic_used_memory + backend_used_memory + shared_used_memory 即可。
名称 |
类型 |
描述 |
|---|---|---|
nodename |
text |
节点名称。 |
memorytype |
text |
|
memorymbytes |
integer |
内存类型分配内存的大小。 |
9. 性能参考
性能测试以一台 x86_64 机器为基准:
CentOS 7 x86_64, Intel(R) Xeon(R) Gold 6250 CPU @ 3.90GHz / 4.50GHz
以下所有SQL的性能数据都在走缓存的情况下+redo在/dev/shm中 。
服务器信息
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6250 CPU @ 3.90GHz
Stepping: 7
CPU MHz: 1760.522
CPU max MHz: 4500.0000
CPU min MHz: 1200.0000
BogoMIPS: 7800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba rsb_ctxsw ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke avx512_vnni md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities
表定义
struct FUNDREALTABLERECORD
{
char client_id[19];
char fund_account[19];
char money_type[4];
char asset_prop;
double current_balance;
double enable_balance;
double cash_balance;
double check_balance;
double frozen_balance;
double unfrozen_balance;
double entrust_buy_balance;
double real_buy_balance;
double real_sell_balance;
double uncome_buy_balance;
double uncome_sell_balance;
double uncome_correct_balance;
double correct_balance;
double foregift_balance;
double mortgage_balance;
int32_t order_no;
};
索引定义
UFTMDB_INDEX_INFO *GetFundrealtablerecordIndexInfo() {
static UFTMDB_INDEX_INFO lpIndexInfo[] = {
{
{ "idx_u_fund_real", "Set", Categoryfundrealtablerecord },
{
{ "fundrealtablerecordCmpIdx_u_fund_real", fundrealtablerecordCmpIdx_u_fund_real, "fund_account asc, money_type asc" },
{ NULL, NULL, NULL }
}
},
{ { NULL, NULL, 0 }, { { NULL, NULL, NULL} } },
{ { "u_fund_account", NULL, 105 }, { { NULL, NULL, NULL} } },
{ { NULL, NULL, 0 }, { { NULL, NULL, NULL} } },
{ { NULL, NULL, 0 }, { { NULL, NULL, NULL} } },
};
return lpIndexInfo;
}
索引比较函数
int32_t fundrealtablerecordCmpIdx_u_fund_real(void *left, void *right) {
FUNDREALTABLERECORD *lpLeft = (FUNDREALTABLERECORD *) left;
FUNDREALTABLERECORD *lpRight = (FUNDREALTABLERECORD *) right;
int cmp_fund_account = strcmp(lpLeft->fund_account, lpRight->fund_account);
if (cmp_fund_account < 0) {
return LESS;
} else if (cmp_fund_account > 0) {
return GREATER;
}
int cmp_money_type = strcmp(lpLeft->money_type, lpRight->money_type);
if (cmp_money_type < 0) {
return LESS;
} else if (cmp_money_type > 0) {
return GREATER;
}
return EQUAL;
}
9.1. 增删改查单条记录耗时(ns)
(ARM 数据待更新)
平台 |
接口 |
插入 |
查询 |
更新(索引) |
删除 |
sum(秒) |
|---|---|---|---|---|---|---|
X86 |
SQL |
21726 |
26688 |
21257 |
17680 |
0.65 |
9.2. 并发测试性能数据
(ARM 数据待更新)
平台 |
接口 |
功能 |
1线程 |
2线程 |
4线程 |
8线程 |
16线程 |
|---|---|---|---|---|---|---|---|
X86 |
SQL |
插入 |
46025.90 |
84814.80 |
163414.00 |
278434.00 |
287670.00 |
X86 |
SQL |
删除 |
56559.70 |
95907.90 |
154654.00 |
159896.00 |
126563.00 |
X86 |
SQL |
更新 |
47042.20 |
82573.20 |
158306.00 |
248292.00 |
225797.00 |
X86 |
SQL |
查询 |
37469.50 |
70913.40 |
104478.00 |
133834.00 |
123064.00 |
平台 |
接口 |
功能 |
1线程 |
2线程 |
4线程 |
8线程 |
16线程 |
|---|---|---|---|---|---|---|---|
X86 |
SQL |
插入 |
21726 |
23580 |
24477 |
28732 |
55619 |
X86 |
SQL |
删除 |
17680 |
20853 |
25864 |
50032 |
126419 |
X86 |
SQL |
更新 |
21257 |
24220 |
25267 |
32220 |
70860 |
X86 |
SQL |
查询 |
26688 |
28203 |
38285 |
59775 |
130013 |
10. 使用限制
当前的 SQL 内存引擎在使用 MDB 表时存在一些功能上的限制,如下:
使用
OR条件走不了索引。受到目前的实现限制,目前对 MDB 表使用
OR条件查询时无法使用Bitmap Index Scan,导致OR条件无法正常走索引。UPDATE FROM关联表更新锁定范围错误。受到目前实现方式的限制,会导致锁记录范围异常增大,建议先不要使用该特性。