1.3.2.2.9. 转换为 GaussDB-Oracle
1.3.2.2.9.1. 数值函数
1.3.2.2.9.1.1. BITAND
- 语法
BITAND (expr1,expr2)- 描述
- 该函数将其输入参数进行二进制按位与操作
参数解释
参数 |
说明 |
|
|---|---|---|
expr1 |
参数1 |
NUMBER 类型表达式 |
expr2 |
参数2 |
NUMBER 类型表达式 |
警告
参数2为负的情况需要包一层括号,例如:BITAND(0,(-1))。
示例
-- 转换前Oracle SQL:
SELECT BITAND(0,0),BITAND(0,(-1)),BITAND(0,NULL),BITAND(-1,2) FROM DUAL;
BITAND(0,0)|BITAND(0,(-1))|BITAND(0,NULL)|BITAND(-1,2)|
-----------+--------------+--------------+------------+
0| 0| | 2|
-- 转换后GaussDB-Oracle SQL:
SELECT BITAND(0, 0),BITAND(0, (-1)),BITAND(0, NULL),BITAND(-1, 2) FROM sys_dummy;
BITAND |BITAND |BITAND |BITAND |
--------+--------+--------+--------+
0| 0| NULL | 2|
1.3.2.2.9.1.2. DBMS_RANDOM.VALUE(暂不支持)
- 语法
DBMS_RANDOM.VALUE- 描述
- 随机生成 [0,1) 范围内的数字,精度为 38 位
示例
-- 转换前Oracle SQL:
SELECT DBMS_RANDOM.VALUE from dual;
VALUE |
----------------------------------------+
0.90603062118926722027812535155007101231|
-- 转换后GaussDB-Oracle SQL:
.. SELECT random()
.. random |
.. ------------------+
.. 0.6059267559984995|
1.3.2.2.9.1.3. DBMS_RANDOM.RANDOM(暂不支持)
- 语法
DBMS_RANDOM.RANDOM- 描述
- 随机生成 [-2^31,2^31)范围内的整数。
-- 转换前Oracle SQL:
SELECT DBMS_RANDOM.RANDOM from dual;
RANDOM |
----------+
-886930169|
-- 转换后GaussDB-Oracle SQL:
.. SELECT CAST(CAST(random() AS numeric)*power(2, 32)-power(2, 31) AS numeric(38,0))
.. numeric |
.. -----------+
.. -1109521446|
1.3.2.2.9.2. 字符串函数
1.3.2.2.9.2.1. REGEXP_REPLACE
语法
REGEXP_REPLACE(source_char, pattern
[, replace_string
[, position
[, occurrence
[, match_param ]
]
]
]
)
- 描述
- 该函数将字符串 source_char 中与正则表达式相匹配的字符替换为 replace_string 中的字符。
参数解释
参数 |
说明 |
|---|---|
source_char |
指定用作搜索值的字符表达式。它通常是一种字符列。数据类型可以是 CHAR、VARCHAR2、NCHAR、NVARCHAR2 或 CLOB 。 |
pattern |
指定正则表达式,它通常是一个文本文字,数据类型可以是 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2。 |
replace_string |
表示替换的字符,可以是 CHAR、VARCHAR2、NCHAR、NVARCHAR2 或 CLOB 类型。 |
position |
指定开始正则表达式匹配的起始位置,取值是一个正整数,为可选项。默认值是 1,表示从第一个字符开始搜索 source_char。 |
occurrence |
指定替换操作的第几个匹配项,是一个非负整数。 |
match_param |
数据类型 VARCHAR2 或 CHAR 的字符表达式,它允许您更改函数的默认匹配行为。 |
match_param取值 |
说明 |
|---|---|
i |
表示大小写不敏感。 |
c |
表示大小写敏感。 |
n |
表示句点 . 可以匹配换行符。 |
m |
表示多行模式。 |
x |
表示忽略空格字符,默认情况下,空格字符会相互匹配。 |
警告
GaussDB-Oracle 最多只支持三个参数。
示例
-- 转换前Oracle SQL:
SELECT REGEXP_REPLACE('china', '(.)', '\1 '),REGEXP_REPLACE('Jane Doe','Jane', 'John'),REGEXP_REPLACE('515.123.4444','([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})','(\1) \2-\3') "REGEXP_REPLACE",REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA','( ){2,}', ' ') FROM DUAL;
REGEXP_REPLACE('CHINA','(.)','\1')|REGEXP_REPLACE('JANEDOE','JANE','JOHN')|REGEXP_REPLACE|REGEXP_REPLACE('500ORACLEPARKWAY,REDWOODSHORES,CA','(){2,}','')|
----------------------------------+---------------------------------------+--------------+---------------------------------------------------------------+
c h i n a |John Doe |(515) 123-4444|500 Oracle Parkway, Redwood Shores, CA |
-- 转换后GaussDB-Oracle SQL:
SELECT REGEXP_REPLACE('china', '(.)', '\1 ', 'g'),REGEXP_REPLACE('Jane Doe', 'Jane', 'John', 'g'),REGEXP_REPLACE('515.123.4444', '([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})', '(\1) \2-\3', 'g') AS "REGEXP_REPLACE",REGEXP_REPLACE('500 Oracle Parkway, Redwood Shores, CA', '( ){2,}', ' ', 'g')
regexp_replace|regexp_replace|REGEXP_REPLACE|regexp_replace |
--------------+--------------+--------------+--------------------------------------+
c h i n a |John Doe |(515) 123-4444|500 Oracle Parkway, Redwood Shores, CA|
1.3.2.2.9.2.2. SUBSTR
语法
SUBSTR(str, pos)
SUBSTR(str, pos, len)
- 描述
- 返回 str 的子字符串,起始位置为 pos,长度为 len。参数中包含 NULL 时,返回 NULL
参数解释
参数 |
说明 |
|---|---|
str |
要操作的字符串 |
pos |
子字符串的起始位置 |
len |
子字符串的长度 |
示例
-- 转换前Oracle SQL:
SELECT SUBSTR('abcdefg', 3),SUBSTR('abcdefg', 3, 2),SUBSTR('abcdefg', -3),SUBSTR('abcdefg', 3, -2) FROM DUAL;
-------------------+---------------------+--------------------+----------------------+
SUBSTR('ABCDEFG',3)|SUBSTR('ABCDEFG',3,2)|SUBSTR('ABCDEFG',-3)|SUBSTR('ABCDEFG',3,-2)|
-------------------+---------------------+--------------------+----------------------+
cdefg |cd |efg | |
-- 转换后GaussDB-Oracle SQL:
SELECT SUBSTR('abcdefg', 3),SUBSTR('abcdefg', 3, 2),SUBSTR('abcdefg', -3),SUBSTR('abcdefg', 3, -2) FROM sys_dummy;
substr|substr|substr|substr|
------+------+------+------+
cdefg |cd |efg |[NULL]|
1.3.2.2.9.2.3. TRIM
- 语法
TRIM([[{BOTH | LEADING | TRAILING}] FROM] str- 描述
- 删除字符串所有前缀和/或后缀,默认为 BOTH。参数中包含 NULL 时,返回 NULL
参数解释
参数 |
说明 |
|---|---|
BOTH |
删除字符串所有前缀和后缀 |
LEADING |
删除字符串前缀 |
TRAILING |
删除字符串后缀 |
str |
要操作的字符串 |
示例
-- 转换前Oracle SQL:
SELECT TRIM(' bar '),TRIM(LEADING 'x' FROM 'xxxbarxxx'), TRIM(BOTH 'x' FROM 'xxxbarxxx'),TRIM(TRAILING 'x' FROM 'xxxbarxxx'),TRIM(BOTH 'x' FROM NULL),TRIM(NULL) FROM DUAL;
TRIM('BAR')|TRIM(LEADING'X'FROM'XXXBARXXX')|TRIM(BOTH'X'FROM'XXXBARXXX')|TRIM(TRAILING'X'FROM'XXXBARXXX')|TRIM(BOTH'X'FROMNULL)|TRIM(NULL)|
-----------+-------------------------------+----------------------------+--------------------------------+---------------------+----------+
bar |barxxx |bar |xxxbar | | |
-- 转换后GaussDB-Oracle SQL:
SELECT TRIM(' bar '),TRIM(LEADING 'x' FROM 'xxxbarxxx'),TRIM(BOTH 'x' FROM 'xxxbarxxx'),TRIM(TRAILING 'x' FROM 'xxxbarxxx'),TRIM(BOTH 'x' FROM NULL),TRIM(NULL) FROM sys_dummy
btrim|ltrim |btrim|rtrim |btrim|btrim|
-----+------+-----+------+-----+-----+
bar |barxxx|bar |xxxbar| | |
1.3.2.2.9.2.4. LENGTHB
- 语法
LENGTHB(str)- 描述
- 该函数返回 str 的字节长度,与字符集有关
参数解释
参数 |
说明 |
|---|---|
str |
要操作的字符串 |
示例
-- 转换前Oracle SQL:
SELECT LENGTHB('中国'), LENGTHB('hello') FROM DUAL;
LENGTHB('中国')|LENGTHB('HELLO')|
-------------+----------------+
6| 5|
-- 转换后GaussDB-Oracle SQL:
SELECT LENGTHB('中国'),LENGTHB('hello') FROM sys_dummy;
octet_length|octet_length|
------------+------------+
6| 5|
1.3.2.2.9.3. 时间日期函数
1.3.2.2.9.3.1. ADD_MONTHS
- 语法
ADD_MONTHS(date, n)- 描述
- 该函数功能是返回日期 date 加上 n 个月后的日期值。
参数解释
参数 |
说明 |
|---|---|
date |
指定日期。该参数为 DATE 数据类型。 |
n |
整数或可以转换为一个整数的任意值。NUMBER 数据类型。 |
示例
-- 转换前Oracle SQL:
SELECT
ADD_MONTHS(CURRENT_DATE,-3) AS a1,
ADD_MONTHS(CURRENT_DATE, 3)AS a2,
ADD_MONTHS(CURRENT_DATE, 1.1)AS a3,
ADD_MONTHS(CURRENT_DATE, 1.5)AS a4,
ADD_MONTHS(CURRENT_DATE, 1.8)AS a5,
ADD_MONTHS(CURRENT_DATE, 0)AS a6
FROM DUAL;
A1 |A2 |A3 |A4 |A5 |A6 |
-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+
2023-09-22 15:25:08.000|2024-03-22 15:25:08.000|2024-01-22 15:25:08.000|2024-01-22 15:25:08.000|2024-01-22 15:25:08.000|2023-12-22 15:25:08.000|
-- 转换后GaussDB-Oracle SQL:
SELECT ADD_MONTHS(localtimestamp(0), -3) AS a1,ADD_MONTHS(localtimestamp(0), 3) AS a2,ADD_MONTHS(localtimestamp(0), 1.1) AS a3,ADD_MONTHS(localtimestamp(0), 1.5) AS a4,ADD_MONTHS(localtimestamp(0), 1.8) AS a5,ADD_MONTHS(localtimestamp(0), 0) AS a6 FROM sys_dummy
a1 |a2 |a3 |a4 |a5 |a6 |
-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+
2023-09-22 15:26:16.000|2024-03-22 15:26:16.000|2024-01-22 15:26:16.000|2024-01-22 15:26:16.000|2024-01-22 15:26:16.000|2023-12-22 15:26:16.000|
1.3.2.2.9.3.2. CURRENT_DATE
- 语法
CURRENT_DATE- 描述
- 该函数返回当前会话时区的当前日期
参数解释
无
示例
-- 转换前Oracle SQL:
SELECT CURRENT_DATE FROM DUAL;
CURRENT_DATE |
-----------------------+
2023-12-22 15:27:15.000|
-- 转换后GaussDB-Oracle SQL:
SELECT localtimestamp(0) FROM sys_dummy;
localtimestamp |
-----------------------+
2023-12-22 15:28:04.000|
1.3.2.2.9.3.3. CURRENT_TIMESTAMP
- 语法
CURRENT_TIMESTAMP- 描述
- 该函数返回当前会话时区中的当前日期
参数解释
无
示例
-- 转换前Oracle SQL:
SELECT CURRENT_TIMESTAMP FROM DUAL;
CURRENT_TIMESTAMP |
-----------------------------+
2023-12-22 15:28:21.307 +0800|
-- 转换后GaussDB-Oracle SQL:
SELECT CURRENT_TIMESTAMP(0) FROM sys_dummy;
current_timestamp |
-----------------------+
2023-12-22 15:28:45.000|
1.3.2.2.9.3.4. LAST_DAY
- 语法
LAST_DAY(date)- 描述
- 返回 date 当月最后一天的日期值
参数解释
参数 |
说明 |
|---|---|
date |
日期类型参数 |
示例
-- 转换前Oracle SQL:
SELECT LAST_DAY(SYSDATE),LAST_DAY(TO_DATE('2023/09/21','YYYY/MM/DD')) FROM DUAL;
LAST_DAY(SYSDATE) |LAST_DAY(TO_DATE('2023/09/21','YYYY/MM/DD'))|
-----------------------+--------------------------------------------+
2023-12-31 14:05:54.000| 2023-09-30 00:00:00.000|
-- 转换后GaussDB-Oracle SQL:
SELECT LAST_DAY(sysdate),LAST_DAY(TO_DATE('2023/09/21', 'YYYY/MM/DD')) FROM sys_dummy;
last_day |last_day |
-----------------------+-----------------------+
2023-12-31 09:44:53.000|2023-09-30 00:00:00.000|
1.3.2.2.9.3.5. MONTHS_BETWEEN
- 语法
MONTHS_BETWEEN (date1,date2)- 描述
- 该函数是返回参数 date1 到 date2 之间的月数
参数解释
参数 |
说明 |
|---|---|
date1 |
DATE 数据类型的值。DATE表示的日期范围可以是公元前4712年1月1日至公元9999年12月31日 |
date2 |
DATE 数据类型的值。DATE表示的日期范围可以是公元前4712年1月1日至公元9999年12月31日 |
注意
由于在目标库Gaussdb-Oracle中没有对应的MONTHS_BETWEEN函数实现,通过统一SQL转换后,将被转换成unisql.months_between函数输出, 对于MONTHS_BETWEEN函数的两个参数,通过统一SQL会原模原样转化,转换后的语句可能会无法执行或者执行结果和Oracle不一致。 需要注意:
在oracle中:
MONTHS_BETWEEN函数的参数理论为DATE类型,Oracle数据对于实际传参为字面量字符串、字符的列,且字符串格式是NLS_DATE_FORMAT格式,会发生隐式转化,函数也会执行成功;
MONTHS_BETWEEN函数的参数可支持传入参数为TIMESTAMP,Oracle的TIMESTAMP的秒的精度为9;
MONTHS_BETWEEN函数的参数可支持传入参数为TIMESTAMP(p) WITH TIME ZONE;
MONTHS_BETWEEN函数结果可为整数、小数。
在Oracle2GuassDB-Oracle中:
unisql.months_between函数的参数仅支持DATE类型,TIMESTAMP类型,字面量字符串格式为YYYY-MM-DD、YYYY-MM-DD HH24:MI:SS、YYYYMMDD,字面量字符串格式值中不允许含空格;
unisql.months_between函数的参数也可以传入参数为TIMESTAMP,GuassDB-Oracle的TIMESTAMP的秒的精度为6,超过6位,不支持;
unisql.months_between是对于TIMESTAMP(p) WITH TIME ZONE这种带时区的值转化的结果与Oracle不一致的,不支持使用;
unisql.months_between函数结果只为小数,与Oracle的MONTHS_BETWEEN函数结果的误差范围为0.00001%,所以再用unisql.months_between值去拼接、运算后结果与Oracle不一致的。
示例
-- 准备数据
CREATE TABLE months_between_results (
id NUMBER PRIMARY KEY,
col_timestamp_1 TIMESTAMP,
col_timestamp_2 TIMESTAMP,
col_date_1 DATE,
col_date_2 DATE,
col_varchar2 varchar2(128),
months_diff NUMBER DEFAULT months_between(TO_DATE('2023-06-11 14:30:00', 'YYYY-MM-DD HH24:MI:SS'), TO_DATE('2023-07-11 14:32:22', 'YYYY-MM-DD HH24:MI:SS')))
INSERT INTO months_between_results (id, col_timestamp_1, col_timestamp_2,col_date_1,col_date_2,col_varchar2) VALUES
(1, TO_DATE('20220611', 'YYYY-MM-DD'), TO_DATE('2023-07-11 14:32:22', 'YYYY-MM-DD HH24:MI:SS'),
TO_TIMESTAMP('2022-06-19 14:32:22.123', 'YYYY-MM-DD HH24:MI:SS.FF'), TO_TIMESTAMP('2023-07-11 14:32:22.456', 'YYYY-MM-DD HH24:MI:SS.FF'),
'2025-11-11 07:32:22.123'
)
INSERT INTO months_between_results (id, col_timestamp_1, col_timestamp_2,col_date_1,col_date_2,col_varchar2) VALUES
(2, TO_DATE('2021-12-11 23:32:22', 'YYYY-MM-DD HH24:MI:SS'), TO_DATE('2023-07-11 14:32:22', 'YYYY-MM-DD HH24:MI:SS'),
TO_TIMESTAMP('2022-06-19 14:32:22.123', 'YYYY-MM-DD HH24:MI:SS.FF'), TO_TIMESTAMP('2023-08-11 14:32:22.456', 'YYYY-MM-DD HH24:MI:SS.FF'),
'2021-09-11 17:39:59.123'
)
INSERT INTO months_between_results (id, col_timestamp_1, col_timestamp_2,col_date_1,col_date_2,col_varchar2) VALUES
(3, TO_DATE('2021-12-11', 'YYYY-MM-DD'), TO_DATE('2023-07-11', 'YYYY-MM-DD'),
TO_TIMESTAMP('2022-06-19 14:32:22.123', 'YYYY-MM-DD HH24:MI:SS.FF'), TO_TIMESTAMP('2023-08-11 14:32:22.456', 'YYYY-MM-DD HH24:MI:SS.FF'),
'2021-09-11 17:39:59'
)
INSERT INTO months_between_results (id, col_timestamp_1, col_timestamp_2,col_date_1,col_date_2,col_varchar2) VALUES
(4, TO_DATE('2021-12-11', 'YYYY-MM-DD'), TO_DATE('2021-11-11', 'YYYY-MM-DD'),
TO_TIMESTAMP('2021-11-11', 'YYYY-MM-DD'), TO_TIMESTAMP('2023-08-11 14:32:22.456', 'YYYY-MM-DD HH24:MI:SS.FF'),
'2021-09-11 17:39:59'
)
-- 转换前Oracle SQL:
SELECT MONTHS_BETWEEN(col_timestamp_1,col_date_1) FROM months_between_results;
MONTHS_BETWEEN(COL_TIMESTAMP_1,COL_DATE_1) |
-------------------------------------------+
-0.2776067801672640382317801672640382317802|
-6.24596774193548387096774193548387096774|
-6.27760678016726403823178016726403823178|
1|
-- 转换后GuassDB-Oracle SQL:
SELECT unisql.months_between(col_timestamp_1, col_date_1) FROM months_between_results;
months_between |
--------------------+
-0.27760678016726403|
-6.245967741935484|
-6.277606780167264|
1.0|
1.3.2.2.9.3.6. NUMTODSINTERVAL
- 语法
NUMTODSINTERVAL (n,interval_unit)- 描述
- 该函数是把参数 n 转为以参数 interval_unit 为单位的 INTERVAL DAY TO SECOND 数据类型的值
参数解释
参数 |
说明 |
|---|---|
n |
NUMBER 数据类型或可以转换为 NUMBER 数据类型的表达式。 |
interval_unit |
单位值。取值为 DAY(天)、HOUR(小时)、MINUTE(分钟)、SECOND(秒),不区分大小写。 |
示例
警告
结果格式或表现存在不一致的情况。如果对数据完全一致要求较高,建议不使用该特性或对结果进一步处理。
-- 转换前Oracle SQL:
SELECT SYSDATE+NUMTODSINTERVAL(3,'DAY'),NUMTODSINTERVAL(2,'day') FROM dual;
SYSDATE+NUMTODSINTERVAL(3,'DAY')|NUMTODSINTERVAL(2,'DAY')|
--------------------------------+------------------------+
2023-12-24 09:54:11.000|2 0:0:0.0 |
-- 转换后GaussDB-Oracle SQL:
SELECT sysdate+NUMTODSINTERVAL(3, 'DAY'),NUMTODSINTERVAL(2, 'day') FROM sys_dummy;
?column? |NUMTODSINTERVAL |
-----------------------+---------------------------------------------+
2023-12-24 09:54:11.000|0 years 0 mons 2 days 0 hours 0 mins 0.0 secs|
1.3.2.2.9.3.7. SYSDATE
- 语法
SYSDATE- 描述
- 返回当前日期和时间
- 参数解释
- 无
示例
-- 转换前Oracle SQL:
SELECT SYSDATE FROM DUAL;
SYSDATE |
-----------------------+
2023-12-21 09:56:26.240|
-- 转换后GaussDB-Oracle SQL:
SELECT sysdate FROM sys_dummy;
statement_timestamp |
-----------------------+
2023-12-21 09:56:26.240|
1.3.2.2.9.3.8. SYSTIMESTAMP
- 语法
SYSTIMESTAMP- 描述
- 该函数返回系统当前日期和时间,返回值的秒的小数位包含 6 位精度,包含当前时区信息,依赖于当前数据库服务器所在操作系统的时区
- 参数解释
- 无
示例
-- 转换前Oracle SQL:
SELECT SYSTIMESTAMP,SYSTIMESTAMP(0),SYSTIMESTAMP(1),SYSTIMESTAMP(2),SYSTIMESTAMP(3),SYSTIMESTAMP(4),SYSTIMESTAMP(5),SYSTIMESTAMP(6),SYSTIMESTAMP(7),SYSTIMESTAMP(8),SYSTIMESTAMP(9) FROM DUAL;
SYSTIMESTAMP |SYSTIMESTAMP(0) |SYSTIMESTAMP(1) |SYSTIMESTAMP(2) |SYSTIMESTAMP(3) |SYSTIMESTAMP(4) |SYSTIMESTAMP(5) |SYSTIMESTAMP(6) |SYSTIMESTAMP(7) |SYSTIMESTAMP(8) |SYSTIMESTAMP(9) |
-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
2023-12-21 10:04:30.543 +0800|2023-12-21 10:04:31.000 +0800|2023-12-21 10:04:30.500 +0800|2023-12-21 10:04:30.540 +0800|2023-12-21 10:04:30.544 +0800|2023-12-21 10:04:30.543 +0800|2023-12-21 10:04:30.543 +0800|2023-12-21 10:04:30.543 +0800|2023-12-21 10:04:30.543 +0800|2023-12-21 10:04:30.543 +0800|2023-12-21 10:04:30.543 +0800|
-- 转换后GaussDB-Oracle SQL:
SELECT statement_timestamp(),SYSTIMESTAMP(0),SYSTIMESTAMP(1),SYSTIMESTAMP(2),SYSTIMESTAMP(3),SYSTIMESTAMP(4),SYSTIMESTAMP(5),SYSTIMESTAMP(6),SYSTIMESTAMP(7),SYSTIMESTAMP(8),SYSTIMESTAMP(9) FROM sys_dummy;
statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |statement_timestamp |
-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+-----------------------+
2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|2023-12-21 09:58:47.767|
1.3.2.2.9.3.9. TRUNC
- 语法
TRUNC(date,[fmt])- 描述
- 该函数返回以参数 fmt 为单位距离的离指定日期 date 最近的日期时间值,并且返回的日期值在 date 之前
参数解释
参数 |
说明 |
|---|---|
date |
DATE 数据类型 |
fmt |
指定了函数返回值与 date 的距离单位 |
fmt的取值如下:
fmt 参数的取值 |
说明 |
|---|---|
j |
默认值,最近 0 点日期。 |
day、dy、d |
返回离指定日期最近的星期日。 |
month、mon、mm、rm |
返回离指定日期最近的月的第一天日期。 |
q |
返回离指定日期最近的季的日期。 |
yyyy、yyy、yy、y |
多个 y 表示不同的精度,返回离指定日期最近的年的第一个日期。 |
cc、scc |
返回离指定日期最近的世纪的初日期。 |
示例
-- 转换前Oracle SQL:
SELECT TRUNC(TO_DATE('2022/04/19 10:32:34', 'YYYY/MM/DD HH24:MI:SS'), 'YEAR'),TRUNC(TO_DATE('2022/04/19 10:32:34', 'YYYY/MM/DD HH24:MI:SS'), 'MONTH'),TRUNC(TO_DATE('2022/04/19 10:32:34', 'YYYY/MM/DD HH24:MI:SS'), 'DDD')FROM DUAL;
TRUNC(TO_DATE('2022/04/1910:32:34','YYYY/MM/DDHH24:MI:SS'),'YEAR')|TRUNC(TO_DATE('2022/04/1910:32:34','YYYY/MM/DDHH24:MI:SS'),'MONTH')|TRUNC(TO_DATE('2022/04/1910:32:34','YYYY/MM/DDHH24:MI:SS'),'DDD')|
------------------------------------------------------------------+-------------------------------------------------------------------+-----------------------------------------------------------------+
2022-01-01 00:00:00.000| 2022-04-01 00:00:00.000| 2022-04-19 00:00:00.000|
-- 转换后GaussDB-Oracle SQL:
SELECT TRUNC(TO_DATE('2022/04/19 10:32:34', 'YYYY/MM/DD HH24:MI:SS'), 'YEAR'),TRUNC(TO_DATE('2022/04/19 10:32:34', 'YYYY/MM/DD HH24:MI:SS'), 'MONTH'),TRUNC(TO_DATE('2022/04/19 10:32:34', 'YYYY/MM/DD HH24:MI:SS'), 'DDD') FROM sys_dummy
trunc |trunc |trunc |
-----------------------+-----------------------+-----------------------+
2022-01-01 00:00:00.000|2022-04-01 00:00:00.000|2022-04-19 00:00:00.000|
1.3.2.2.9.3.10. TO_DSINTERVAL
语法
/*SQL 日期格式*/
TO_DSINTERVAL ('[+ | -] days hours:minutes:seconds[.frac_secs]')
/*ISO 日期格式*/
TO_DSINTERVAL ('[-] P[days D]
[T[hours H][minutes M][seconds[.frac_secs]S]]')
- 描述
- 该函数将一个 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的字符串转换为一个 INTERVAL DAY TO SECOND 数据类型的值
参数解释
参数 |
说明 |
|
|---|---|---|
[+ | -]days hours:minutes:seconds[.frac_secs] |
符合该参数格式的 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的字符串。 |
|
[-] P[days D] [T[hours H][minutes M][seconds[.frac_secs]S] |
符合该参数格式的 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的字符串。注意 值中不允许有空格。 |
|
frac_secs |
表示秒的小数部分,取整数值,范围为 [0 999999999]。 | |
|
days 表示天,取整数值,范围为 [0,999999999]。
hours 表示小时,取整数值,范围为 [0,23]。
minutes 表示分钟,取整数值,范围为 [0,59]。
seconds 表示秒,取整数值,范围为 [0,59]。
示例
-- 转换前Oracle SQL:
SELECT TO_DSINTERVAL('100 00:00:00'),TO_DSINTERVAL('P100DT05H') FROM DUAL;
TO_DSINTERVAL('10000:00:00')|TO_DSINTERVAL('P100DT05H')|
----------------------------+--------------------------+
100 0:0:0.0 |100 5:0:0.0 |
-- 转换后GaussDB-Oracle SQL:
SELECT CAST('100 00:00:00' AS INTERVAL),CAST('P100DT05H' AS INTERVAL) FROM sys_dummy;
interval |interval |
-----------------------------------------------+-----------------------------------------------+
0 years 0 mons 100 days 0 hours 0 mins 0.0 secs|0 years 0 mons 100 days 5 hours 0 mins 0.0 secs|
1.3.2.2.9.3.11. TO_YMINTERVAL
语法
/*SQL 日期格式*/
TO_YMINTERVAL([+|-] years-months)
/*ISO 日期格式*/
TO_YMINTERVAL([-]P[ years Y][months M][days D][T[hours H][minutes M][seconds[.frac_secs]S]])
- 描述
- 该函数将一个 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的字符串转换为一个 INTERVAL YEAR TO MONTH 数据类型的值
参数解释
参数 |
说明 |
||
|---|---|---|---|
[+|-] years-months |
符合该参数格式的 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的字符串。years 表示年,取整数值,范围为 [0 999999999]。months 表示月,取整数值,范围为 [0 | 11]。 | |
||
[-]P[ years Y][months M][days D][T[hours H][minutes M][seconds[.frac_secs]S]] |
符合该参数格式的 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的字符串。 frac_secs 表示秒的小数部分,取整数值,范围是[0 999999999]。注意 值中不允许有空格。 | |
||
示例
-- 转换前Oracle SQL:
SELECT SYSDATE,SYSDATE+TO_YMINTERVAL('01-02') FROM DUAL;
SYSDATE |SYSDATE+TO_YMINTERVAL('01-02')|
-----------------------+------------------------------+
2023-12-21 10:15:15.000| 2025-02-21 10:15:15.000|
-- 转换后GaussDB-Oracle SQL:
SELECT sysdate,sysdate+CAST('01-02' AS INTERVAL) FROM sys_dummy;
sysdate |?column? |
-----------------------+-----------------------+
2023-12-21 10:09:45.154|2025-02-21 10:09:45.154|
1.3.2.2.9.3.12. DAYOFMONTH
- 语法
DAYOFMONTH (date)- 描述
- 该函数是提取参数 date 的天数部分,返回int类型。(MariaDB中内建函数)
参数解释
参数 |
说明 |
|---|---|
date |
DATE 数据类型的值。DATE表示的日期范围可以是公元前4712年1月1日至公元9999年12月31日 |
注意
由于在目标库Gaussdb-Oracle中没有对应的DAYOFMONTH函数实现,通过统一SQL转换后,将被转换成unisql.dayofmonth函数输出, 对于DAYOFMONTH函数的参数,通过统一SQL会原模原样转化,转换后的语句可能会无法执行或者执行结果和MariaDB不一致。 需要注意:
在Oracle2GuassDB-Oracle中:
unisql.dayofmonth函数的参数支持DATE类型,支持的字面量字符串格式为YYYY-MM-DD、YYYY-MM-DD HH24:MI:SS、YYYYMMDD、YYMMDD,字面量字符串格式值中不允许含空格,6位字面量字符串时不支持格式如YY-MM-DD、YY/MM/DD;
unisql.dayofmonth函数的参数也可以传入参数为TIMESTAMP,如unisql.dayofmonth(timestamp '2007-02-03 11:22:33.012');
unisql.dayofmonth函数对于边界日期的处理与MariaDB不同,传入异常的日期时MariaDB通常会返回NULL,而unisql.dayofmonth则会直接报错。比如年、月、日中包含0(例:'2007-02-00')或者超出日期范围(例:'2007-15-20');
示例
CREATE TABLE dayofmonth_test(
d1 INT,
d2 DATE
);
-- 转换前Oracle SQL:
INSERT INTO dayofmonth_test (d1, d2) VALUES (dayofmonth('20070203'), '20070203');
INSERT INTO dayofmonth_test (d1, d2) VALUES (dayofmonth('2007-08-13'), '2007-08-13');
SELECT d1, dayofmonth(d2) FROM dayofmonth_test;
d1|dayofmonth(d2)|
--+--------------+
3| 3|
13| 13|
-- 转换后GuassDB-Oracle SQL:
INSERT INTO dayofmonth_test (d1,d2) VALUES (unisql.dayofmonth('20070203'),'20070203');
INSERT INTO dayofmonth_test (d1,d2) VALUES (unisql.dayofmonth('2007-08-13'),'2007-08-13');
SELECT d1,unisql.dayofmonth(d2) FROM dayofmonth_test
d1|dayofmonth|
--+----------+
3| 3|
13| 13|
1.3.2.2.9.3.13. YEAR
- 语法
YEAR (date)- 描述
- 该函数是提取参数 date 的年份,返回int类型。(MariaDB中内建函数)
参数解释
参数 |
说明 |
|---|---|
date |
DATE 数据类型的值。DATE表示的日期范围可以是公元前4712年1月1日至公元9999年12月31日 |
注意
由于在目标库Gaussdb-Oracle中没有对应的YEAR函数实现,通过统一SQL转换后,将被转换成unisql.year函数输出, 对于YEAR函数的参数,通过统一SQL会原模原样转化,转换后的语句可能会无法执行或者执行结果和MariaDB不一致。 需要注意:
在Oracle2GuassDB-Oracle中:
unisql.year函数的参数支持DATE类型,支持的字面量字符串格式为YYYY-MM-DD、YYYY-MM-DD HH24:MI:SS、YYYYMMDD、YYMMDD,字面量字符串格式值中不允许含空格,6位字面量字符串时不支持格式如YY-MM-DD、YY/MM/DD;
unisql.year函数的参数也可以传入参数为TIMESTAMP,如unisql.year(timestamp '2007-02-03 11:22:33.012');
unisql.year函数对于边界日期的处理与MariaDB不同,传入异常的日期时MariaDB通常会返回NULL,而unisql.year则会直接报错。比如年、月、日中包含0(例:'2007-02-00')或者超出日期范围(例:'2007-15-20');
示例
CREATE TABLE year_func_test(
y1 INT,
y2 DATE
);
-- 转换前Oracle SQL:
INSERT INTO year_func_test (y1, y2) VALUES (year('20070203'), '20070203');
INSERT INTO year_func_test (y1, y2) VALUES (year('2017-08-13'), '2017-08-13');
SELECT y1, year(y2) FROM year_func_test;
y1 |year(y2)|
----+--------+
2007| 2007|
2017| 2017|
-- 转换后GuassDB-Oracle SQL:
INSERT INTO year_func_test (y1,y2) VALUES (unisql.year('20070203'),'20070203');
INSERT INTO year_func_test (y1,y2) VALUES (unisql.year('2017-08-13'),'2017-08-13');
SELECT y1,unisql.year(y2) FROM year_func_test;
y1 |year|
----+----+
2007|2007|
2017|2017|
1.3.2.2.9.3.14. NUMTODSINTERVAL
- 语法
NUMTODSINTERVAL(number, 'interval_unit')- 描述
- 该函数作用是将一个数值表达式加时间间隔单位转换为一个 INTERVAL DAY TO SECOND 数据类型的值。可以用来对一个日期时间值进行加减计算。
参数解释
参数 |
说明 |
|---|---|
number |
指定间隔数量,是一个 NUMBER 值或可以隐式转换为 NUMBER 值的表达式。 |
interval_unit |
指定间隔单位,可以是 CHAR、VARCHAR2、NCHAR 或 NVARCHAR2 数据类型的值,不区分大小写。默认情况下,返回的精度为 9 |
interval_unit的取值如下:
DAY, 表示天。
HOUR, 表示小时。
MINUTE ,表示分钟。
SECOND, 表示秒。
示例
-- 转换前Oracle SQL:
SELECT NUMTODSINTERVAL(10,'day'),
NUMTODSINTERVAL(10,'HOUR'),
NUMTODSINTERVAL(10,'MINUTE'),
NUMTODSINTERVAL(10,'SECOND')
FROM DUAL;
NUMTODSINTERVAL(10,'DAY')|NUMTODSINTERVAL(10,'HOUR')|NUMTODSINTERVAL(10,'MINUTE')|NUMTODSINTERVAL(10,'SECOND')|
-------------------------+--------------------------+----------------------------+----------------------------+
10 0:0:0.0 |0 10:0:0.0 |0 0:10:0.0 |0 0:0:10.0 |
-- 转换后GaussDB-Oracle SQL:
SELECT NUMTODSINTERVAL(10, 'day'),NUMTODSINTERVAL(10, 'HOUR'),NUMTODSINTERVAL(10, 'MINUTE'),NUMTODSINTERVAL(10, 'SECOND') FROM sys_dummy;
NUMTODSINTERVAL |NUMTODSINTERVAL |NUMTODSINTERVAL |NUMTODSINTERVAL |
----------------------------------------------+----------------------------------------------+----------------------------------------------+----------------------------------------------+
0 years 0 mons 10 days 0 hours 0 mins 0.0 secs|0 years 0 mons 0 days 10 hours 0 mins 0.0 secs|0 years 0 mons 0 days 0 hours 10 mins 0.0 secs|0 years 0 mons 0 days 0 hours 0 mins 10.0 secs|
1.3.2.2.9.4. 转换函数
1.3.2.2.9.4.1. TO_CHAR (character)
- 语法
TO_CHAR(character)- 描述
- 该函数将 NCHAR、NVARCHAR2 或 CLOB 类型的数据转换为 VARCHAR2 数据类型。
参数解释
参数 |
说明 |
|---|---|
character |
指定要转换为 VARCHAR2 数据类型表达式,数据类型可以是 NCHAR、NVARCHAR2 或 CLOB |
示例
-- 转换前Oracle SQL:
SELECT TO_CHAR('010101') FROM DUAL;
TO_CHAR('010101')|
-----------------+
010101 |
-- 转换后GaussDB-Oracle SQL:
SELECT TO_CHAR('010101') FROM sys_dummy;
text |
------+
010101|
1.3.2.2.9.4.2. TO_CLOB
- 语法
TO_CLOB(lob_column | char)- 描述
- 该函数将 LOB 列或其他字符串中的 NCLOB 值转换为 CLOB 值。
参数解释
参数 |
说明 |
|---|---|
lob_column |
属于 LOB 列或其他字符串中的 NCLOB 值。 |
char |
属于 CHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOB 或 NCLOB 类型的值。 |
警告
不支持2个及2个以上参数的用法。
示例
-- 创建表,前置数据
CREATE TABLE unisql_test_clob (c1 clob,c2 varchar2(10));
INSERT INTO unisql_test_clob VALUES (TO_CLOB('1'),'orale');
-- 转换前Oracle SQL:
SELECT TO_CLOB(c1),TO_CLOB(c2),TO_CLOB(10) FROM unisql_test_clob;
TO_CLOB(C1)|TO_CLOB(C2)|TO_CLOB(10)|
-----------+-----------+-----------+
1 |orale |10 |
-- 转换后GaussDB-Oracle SQL:
SELECT CAST(c1 AS text),CAST(c2 AS text),CAST(10 AS text) FROM unisql_test_clob;
c1|c2 |text|
--+-----+----+
1 |orale|10 |
1.3.2.2.9.4.3. TO_DATE
- 语法
TO_DATE(char [, fmt])- 描述
- 该函数将 CHAR、VARCHAR、NCHAR 或 NVARCHAR2 数据类型的字符转换为日期数据类型的值
参数解释
参数 |
说明 |
|---|---|
char |
CHAR、VARCHAR、NCHAR 或 NVARCHAR2 数据类型的值 |
fmt |
指定 char 的时间格式 |
示例
-- 转换前Oracle SQL:
select to_date('2012/12/12', 'yyyy-MM-dd'),
to_date('2023-12-02', 'yyyy-mm-dd'),
to_date('2023-12-02 11:23:33', 'yyyy-mm-dd HH24:MI:SS')
FROM DUAL;
TO_DATE('2012/12/12','YYYY-MM-DD')|TO_DATE('2023-12-02','YYYY-MM-DD')|TO_DATE('2023-12-0211:23:33','YYYY-MM-DDHH24:MI:SS')|
----------------------------------+----------------------------------+----------------------------------------------------+
2012-12-12 00:00:00.000| 2023-12-02 00:00:00.000| 2023-12-02 11:23:33.000|
-- 转换后GaussDB-Oracle SQL:
SELECT to_date('2012/12/12', 'yyyy-MM-dd'),to_date('2023-12-02', 'yyyy-mm-dd'),to_date('2023-12-02 11:23:33', 'yyyy-mm-dd HH24:MI:SS') FROM sys_dummy;
to_timestamp |to_timestamp |to_timestamp |
-----------------------+-----------------------+-----------------------+
2012-12-12 00:00:00.000|2023-12-02 00:00:00.000|2023-12-02 11:23:33.000|
1.3.2.2.9.4.4. TO_NUMBER
- 语法
TO_NUMBER(expr)- 描述
- 该函数功能是将 CHAR、VARCHAR2等类型的字符串转换为 NUMBER 数值数据类型的值
参数解释
参数 |
说明 |
|---|---|
expr |
属于 CHAR、VARCHAR2、NCHAR、NVARCHAR2、NUMBER, BINARY_FLOAT 或 BINARY_DOUBLE 数据类型的数值。 |
示例
-- 转换前Oracle SQL:
SELECT TO_NUMBER('0123456'),TO_NUMBER('1.2'),TO_NUMBER('0'),TO_NUMBER(1.2),TO_NUMBER('-1'),TO_NUMBER(-1) FROM DUAL;
TO_NUMBER('0123456')|TO_NUMBER('1.2')|TO_NUMBER('0')|TO_NUMBER(1.2)|TO_NUMBER('-1')|TO_NUMBER(-1)|
--------------------+----------------+--------------+--------------+---------------+-------------+
123456| 1.2| 0| 1.2| -1| -1|
-- 转换后GaussDB-Oracle SQL:
SELECT TO_NUMBER('0123456'),TO_NUMBER('1.2'),TO_NUMBER('0'),TO_NUMBER(1.2),TO_NUMBER('-1'),TO_NUMBER(-1) FROM sys_dummy;
to_number|to_number|to_number|to_number|to_number|to_number|
-------+-------+-------+-------+-------+-------+
123456| 1.2| 0| 1.2| -1| -1|
警告
因为gaussdb-oracle数据库本身实现原因导致对于科学计数法的的to_number函数转换结果精度与oracle不一致,需要注意。
1.3.2.2.9.4.5. TO_NCHAR (character)
- 语法
TO_NCHAR(character)- 描述
- 该函数将 CHAR、VARCHAR2、CLOB 或 NCLOB 类型的数据转换为国家字符集,返回 NVARCHAR2 数据类型。
参数解释
参数 |
说明 |
|---|---|
character |
CHAR、VARCHAR2、CLOB 或 NCLOB 类型的数据 |
示例
-- 创建表,前置数据
CREATE TABLE unisql_test_nchar(col1 INT,col2 VARCHAR2(20));
INSERT INTO unisql_test_nchar VALUES(1,'unisql tool');
-- 转换前Oracle SQL:
SELECT TO_NCHAR(col1),TO_NCHAR(col2) FROM unisql_test_nchar;
TO_NCHAR(COL1)|TO_NCHAR(COL2)|
--------------+--------------+
1 |unisql tool |
-- 转换后GaussDB-Oracle SQL:
SELECT CAST(col1 AS text),CAST(col2 AS text) FROM unisql_test_nchar;
col1|col2 |
----+-----------+
1 |unisql tool|
1.3.2.2.9.5. 编码解码函数
1.3.2.2.9.5.1. DECODE
- 语法
DECODE (condition, search, result [, search, result ...][, default])- 描述
- 该函数功能是将 condition 与每个 search 依次做比较,并返回对比结果
参数解释
参数 |
说明 |
|---|---|
condition |
数值数据类型(NUMBER、FLOAT、BINARY_FLOAT 或 BINARY_DOUBLE)或字符数据类型( CHAR、VARCHAR2、NCHAR 或 NVARCHAR2)的值或表达式 |
search |
数值数据类型(NUMBER、FLOAT、BINARY_FLOAT 或 BINARY_DOUBLE)或字符数据类型( CHAR、VARCHAR2、NCHAR 或 NVARCHAR2)的值或表达式 |
result |
数值数据类型(NUMBER、FLOAT、BINARY_FLOAT 或 BINARY_DOUBLE)或字符数据类型( CHAR、VARCHAR2、NCHAR 或 NVARCHAR2)的值或表达式 |
default |
数值数据类型(NUMBER、FLOAT、BINARY_FLOAT 或 BINARY_DOUBLE)或字符数据类型( CHAR、VARCHAR2、NCHAR 或 NVARCHAR2)的值或表达式 |
示例
-- 转换前Oracle SQL:
SELECT DECODE(SIGN((5*3-2)-(3*4-1)),0,'相等',1,'(5*3-2)大','(3*4-1)大'),
DECODE(INSTR('CLARK','S'), 0, '不含有 S', '含有 S') "CLARK",
DECODE(INSTR('KING','S'), 0, '不含有 S', '含有 S') "KING",
DECODE(INSTR('MILLER','S'), 0, '不含有 S', '含有 S') "MILLER",
DECODE(INSTR('ADAMS','S'), 0, '不含有 S', '含有 S') "ADAMS",
DECODE(INSTR('FORD','S'), 0, '不含有 S', '含有 S') "FORD",
DECODE(INSTR('JONES','S'), 0, '不含有 S', '含有 S') "JONES"
FROM DUAL;
DECODE(SIGN((5*3-2)-(3*4-1)),0,'相等',1,'(5*3-2)大','(3*4-1)大')|CLARK|KING |MILLER|ADAMS|FORD |JONES|
------------------------------------------------------------+-----+-----+------+-----+-----+-----+
(5*3-2)大 |不含有 S|不含有 S|不含有 S |含有 S |不含有 S|含有 S |
-- 转换后GaussDB-Oracle SQL:
SELECT unisql.DECODE(CAST(SIGN((5*3-2)-(3*4-1)) AS text), 0, CAST('相等' AS text), CAST(1 AS text), CAST('(5*3-2)大' AS text), CAST('(3*4-1)大' AS text)),unisql.DECODE(CAST(INSTR('CLARK', 'S') AS text), 0, CAST('不含有 S' AS text), CAST('含有 S' AS text)) AS "CLARK",unisql.DECODE(CAST(INSTR('KING', 'S') AS text), 0, CAST('不含有 S' AS text), CAST('含有 S' AS text)) AS "KING",unisql.DECODE(CAST(INSTR('MILLER', 'S') AS text), 0, CAST('不含有 S' AS text), CAST('含有 S' AS text)) AS "MILLER",unisql.DECODE(CAST(INSTR('ADAMS', 'S') AS text), 0, CAST('不含有 S' AS text), CAST('含有 S' AS text)) AS "ADAMS",unisql.DECODE(CAST(INSTR('FORD', 'S') AS text), 0, CAST('不含有 S' AS text), CAST('含有 S' AS text)) AS "FORD",unisql.DECODE(CAST(INSTR('JONES', 'S') AS text), 0, CAST('不含有 S' AS text), CAST('含有 S' AS text)) AS "JONES"
decode | CLARK | KING | MILLER | ADAMS | FORD | JONES
-----------+----------+----------+----------+--------+----------+--------
(5*3-2)大 | 不含有 S | 不含有 S | 不含有 S | 含有 S | 不含有 S | 含有 S
(1 row)
警告
使用 DECODE 函数解码时,需要注意以下内容:
GaussDB_Oracle限制了DECODE函数中所有参数的类型需保持一致,统一sql的配置参数:unisql.decode.parameters.funcnames 支持将decode函数的参数统一转化为相同类型(支持text、numeric、date、timestamp),前提为decode的参数包含函数且函数名包含在本参数的配置内(多个函数名之间用英文逗号分割)。
示例
--参数配置
unisql.decode.parameters.funcnames = min,max
-- 转换前Oracle SQL:
SELECT DECODE(MAX(col1) ,MIN(col2),'匹配col_Five',99.99,'Ten',MIN(id) ) FROM test_decode;
SELECT DECODE(MAX(col1) ,MIN(col2), clo3,99.99,'Ten',MIN(id) ) FROM test_decode;
SELECT DECODE(MAX(col1) ,1.0, 2.0,99.99,'Ten',MIN(id) ) FROM test_decode;
--转化后GaussDB_Oracle SQL:
SELECT unisql.DECODE(CAST(MAX(col1) AS text), MIN(col2), CAST('匹配col_Five' AS text), CAST(99.99 AS text), CAST('Ten' AS text), CAST(MIN(id) AS text)) FROM test_decode;
SELECT unisql.DECODE(CAST(MAX(col1) AS text), MIN(col2), clo3, CAST(99.99 AS text), CAST('Ten' AS text), CAST(MIN(id) AS text)) FROM test_decode;
SELECT unisql.DECODE(CAST(MAX(col1) AS text), 1.0, 2.0, CAST(99.99 AS text), CAST('Ten' AS text), CAST(MIN(id) AS text)) FROM test_decode;
1.3.2.2.9.6. 空值函数
1.3.2.2.9.6.1. NVL
- 语法
NVL(expr1, expr2)- 描述
- 该函数从两个表达式返回一个非空值。如果 expr1 与 expr2 的结果都为空值,则 NVL 函数返回 NULL
参数解释
参数 |
说明 |
|---|---|
expr1 |
指定第一个参数,数据类型可以是数据库内建数据类型中的任何数据类型。 |
expr2 |
指定第二个参数,数据类型可以是数据库内建数据类型中的任何数据类型。 |
示例
-- 转换前Oracle SQL:
SELECT NVL(10,'1'),NVL(NULL,1),NVL(0/1,1) FROM DUAL;
NVL(10,'1')|NVL(NULL,1)|NVL(0/1,1)|
-----------+-----------+----------+
10| 1| 0|
-- 转换后GaussDB-Oracle SQL:
SELECT coalesce(10, '1'),coalesce(NULL, 1),coalesce(0/1, 1)
coalesce|coalesce|coalesce|
--------+--------+--------+
10| 1| 0|
注意
如果nvl的第二个参数是单个空格字符串(' '),这会将第一个参数包裹一个to_char函数,以解决nvl类型不兼容的问题,该函数包裹后对性能几乎无影响
create table big_table (id int,c1 int,c2 int,c3 int,c4 int,c5 int,c6 int,c7 varchar(10),c8 varchar(10),c9 varchar(10),c10 varchar(10),c11 varchar(10),c12 varchar(10));
-- 以下SQL测试不包裹to_char函数时的插入性能
insert into big_table select generate_series(0,10000000) as id, 100010 as c1,100010 as c2,100010 as c3,100010 as c4,100010 as c5,100010 as c6,100010 as c7,100010 as c8,100010 as c9,100010 as c10,100010 as c11,100010 as c12;
-- 以下SQL测试包裹了to_char函数时的插入性能
insert into big_table select generate_series(0,10000000) as id, to_char(100010) as c1,to_char(100010) as c2,to_char(100010) as c3,to_char(100010) as c4,to_char(100010) as c5,to_char(100010) as c6,to_char(100010) as c7,to_char(100010) as c8,to_char(100010) as c9,to_char(100010) as c10,to_char(100010) as c11,to_char(100010) as c12;
在 gaussdb(GaussDB Kernel 505.0.0.SPC0500 build 284e57f6) 中的测试结果分别为:
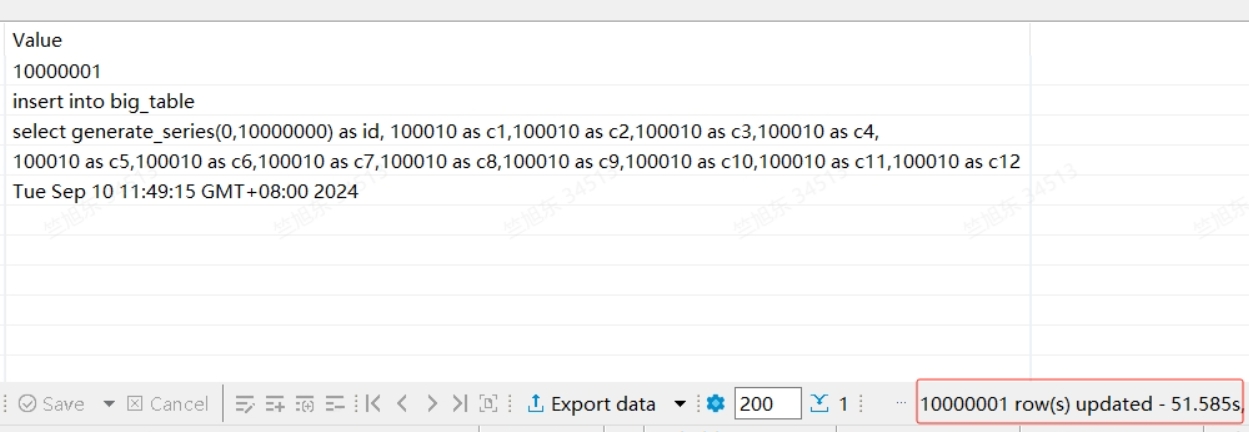
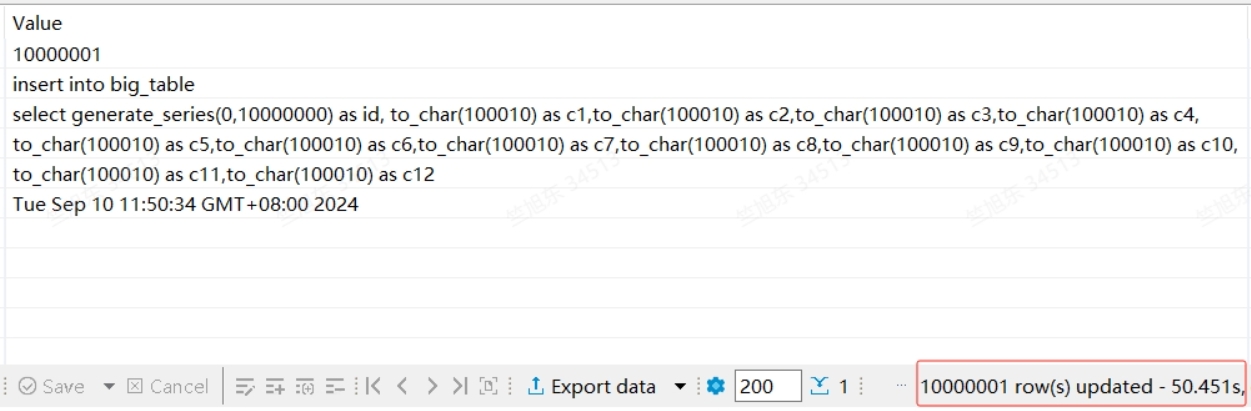
1.3.2.2.9.7. 环境和标识符函数
1.3.2.2.9.7.1. SYS_GUID
- 语法
SYS_GUID()- 描述
- 该函数生成并返回由 16 个字节组成的全局唯一标识符,即生成一个全局唯一序列号
参数解释
无
示例
警告
结果格式或表现存在不一致的情况。如果对数据完全一致要求较高,建议不使用该特性或对结果进一步处理。
-- 转换前Oracle SQL:
SELECT SYS_GUID() FROM DUAL;
SYS_GUID() |
----------------+
íx OH xàc) çt|
-- 转换后GaussDB-Oracle SQL:
SELECT gen_random_uuid()
gen_random_uuid |
------------------------------------+
6b846107-4402-46da-832f-c9738a6e029e|
1.3.2.2.9.8. 聚合函数
1.3.2.2.9.8.1. LISTAGG
- 语法
LISTAGG (measure_expr [,'delimiter']) [ WITHIN GROUP ] (order_by_clause)- 描述
- 该函数用于列转行,LISTAGG 对 ORDER BY 子句中指定的每个组内的数据进行排序,然后合并度量列的值
参数解释
参数 |
说明 |
|---|---|
measure_expr |
可以是任何表达式。度量列中的空值将被忽略。 |
delimiter |
指定用于分隔度量值的字符串。此子句是可选的,默认为 NULL。 |
示例
-- 转换前Oracle SQL:
SELECT LISTAGG(name, '; ') WITHIN GROUP (ORDER BY employee_id,name) AS rk FROM unisql_employee WHERE department_id=1;
RK |
----------------+
JACK; TOM; LINDA|
-- 转换后GaussDB-Oracle SQL:
SELECT STRING_AGG(name, '; ' ORDER BY employee_id,name) AS rk FROM unisql_employee WHERE department_id=1
rk |
----------------+
JACK; TOM; LINDA|
-- 使用语法词ON OVERFLOW TRUNCATE/ON OVERFLOW ERROR
CREATE TABLE listagg_test_employees (
emp_id int,
emp_name VARCHAR(100),
department_id int
);
-- 插入数据
INSERT INTO listagg_test_employees (emp_id, emp_name, department_id) VALUES (1, 'John Doe', 1);
INSERT INTO listagg_test_employees (emp_id, emp_name, department_id) VALUES (2, 'Jane Smith', 1);
INSERT INTO listagg_test_employees (emp_id, emp_name, department_id) VALUES (3, 'Mark Johnson', 2);
INSERT INTO listagg_test_employees (emp_id, emp_name, department_id) VALUES (4, 'Emily Davis', 2);
SELECT LISTAGG(emp_name ON OVERFLOW TRUNCATE) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name, ', ' ON OVERFLOW TRUNCATE) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name, ', ' ON OVERFLOW TRUNCATE) WITHIN GROUP (ORDER BY department_id) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name,', ' ON OVERFLOW TRUNCATE) over(partition by department_id) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name ON OVERFLOW ERROR) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name, ', ' ON OVERFLOW ERROR) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name, ', ' ON OVERFLOW ERROR) WITHIN GROUP (ORDER BY department_id) rk FROM listagg_test_employees;
SELECT LISTAGG(emp_name,', ' ON OVERFLOW ERROR) over(partition by department_id) rk FROM listagg_test_employees;
1.3.2.2.9.8.2. MEDIAN
- 语法
MEDIAN(expr) [ OVER (query_partition_clause) ]- 描述
- 该函数用于返回一组数值的中值,即将一组数值排序后返回居于中间的数值。如果参数集合中包含偶数个数值,该函数将返回位于中间的两个数的平均值。可以将其用作聚合或分析函数。
说明
作为聚合函数使用时,该函数对一组行的集合进行聚合计算,结果只能返回一个值,此时不需要加 OVER 子句。
参数解释
参数 |
说明 |
|---|---|
expr |
指定要求中值的数组名称,参数类型属于数值数据类型或可以隐式转换为数字数据类型。 |
OVER |
使用 OVER 子句定义窗口进行计算。详细信息请参见 分析函数说明。 |
示例
-- 转换前Oracle SQL:
SELECT department_id, MEDIAN(salary) FROM unisql_employee ke GROUP BY department_id;
DEPARTMENT_ID|MEDIAN(SALARY)|
-------------+--------------+
1| 10000|
2| 25000|
3| 50000|
-- 转换后GaussDB-Oracle SQL:
SELECT department_id,percentile_cont(5e-01) WITHIN GROUP (ORDER BY salary) FROM unisql_employee AS ke GROUP BY department_id
department_id|percentile_cont|
-------------+---------------+
1| 10000.0|
2| 25000.0|
3| 50000.0|
1.3.2.2.9.8.3. WM_CONCAT
- 语法
WM_CONCAT([DISTINCT ]expr)- 描述
- 该函数是一个用于将分组内的字符串根据逗号进行拼接的聚合函数。
注意
和 group by 使用时拼接顺序和oracle库中不完全一致。
行展示顺序不一致,建议使用该函数时根据列名进行排序。
存在表达式计算时精度、标度和oracle不完全一致。
暂时不支持和keep、over联合使用。
和聚合函数使用时不支持嵌套使用。例如:SELECT min(CAST(to_char(WM_CONCAT(a.id/2+a.id*2)) AS number)) FROM WM_CONCAT_TEST a GROUP BY a.id;
示例
-- 转换前Oracle SQL:
CREATE TABLE wm_concat_test (
id NUMBER,
name VARCHAR2(100),
department VARCHAR2(100)
);
INSERT INTO wm_concat_test (id, name, department) VALUES (1, 'John', 'IT');
INSERT INTO wm_concat_test (id, name, department) VALUES (2, 'Jane', 'HR');
INSERT INTO wm_concat_test (id, name, department) VALUES (3, 'Tom', 'IT');
INSERT INTO wm_concat_test (id, name, department) VALUES (4, 'Alice', 'Finance');
INSERT INTO wm_concat_test (id, name, department) VALUES (5, 'Bob', 'IT');
INSERT INTO wm_concat_test (id, name, department) VALUES (6, 'Mary', 'HR');
select wm_concat('') from WM_CONCAT_TEST a;
WM_CONCAT('')|
-------------+
|
select wm_concat(null) from WM_CONCAT_TEST a;
WM_CONCAT(NULL)|
---------------+
|
select wm_concat(a.name) from WM_CONCAT_TEST a;
WM_CONCAT(A.NAME) |
----------------------------+
John,Jane,Tom,Alice,Bob,Mary|
select wm_concat(distinct a.name) from WM_CONCAT_TEST a;
WM_CONCAT(DISTINCTA.NAME) |
----------------------------+
Alice,Bob,Jane,John,Mary,Tom|
select wm_concat(a.name || ':'|| a.name) from WM_CONCAT_TEST a;
WM_CONCAT(A.NAME||':'||A.NAME) |
---------------------------------------------------------+
John:John,Jane:Jane,Tom:Tom,Alice:Alice,Bob:Bob,Mary:Mary|
select wm_concat(a.name || ':'|| a.id) from WM_CONCAT_TEST a;
WM_CONCAT(A.NAME||':'||A.ID) |
----------------------------------------+
John:1,Jane:2,Tom:3,Alice:4,Bob:5,Mary:6|
SELECT department, WM_CONCAT(a.name) FROM wm_concat_test a GROUP BY a.department;
DEPARTMENT|WM_CONCAT(A.NAME)|
----------+-----------------+
Finance |Alice |
HR |Jane,Mary |
IT |John,Bob,Tom |
SELECT department, WM_CONCAT(a.name) FROM wm_concat_test a GROUP BY a.department ORDER BY a.department;
DEPARTMENT|WM_CONCAT(A.NAME)|
----------+-----------------+
Finance |Alice |
HR |Jane,Mary |
IT |John,Bob,Tom |
SELECT department, WM_CONCAT(a.name) FROM wm_concat_test a GROUP BY a.department ORDER BY a.department DESC ;
DEPARTMENT|WM_CONCAT(A.NAME)|
----------+-----------------+
IT |John,Bob,Tom |
HR |Jane,Mary |
Finance |Alice |
select wm_concat(a.department) from WM_CONCAT_TEST a;
WM_CONCAT(A.DEPARTMENT)|
-----------------------+
IT,HR,IT,Finance,IT,HR |
select wm_concat(distinct a.department) from WM_CONCAT_TEST a;
WM_CONCAT(DISTINCTA.DEPARTMENT)|
-------------------------------+
Finance,HR,IT |
select wm_concat(a.id+a.id) from WM_CONCAT_TEST a;
WM_CONCAT(A.ID+A.ID)|
--------------------+
2,4,6,8,10,12 |
select wm_concat(a.id+a.id-1) from WM_CONCAT_TEST a;
WM_CONCAT(A.ID+A.ID-1)|
----------------------+
1,3,5,7,9,11 |
select wm_concat(a.id+a.id*2) from WM_CONCAT_TEST a;
WM_CONCAT(A.ID+A.ID*2)|
----------------------+
3,6,9,12,15,18 |
select wm_concat(a.id/2+a.id*2) from WM_CONCAT_TEST a;
WM_CONCAT(A.ID/2+A.ID*2)|
------------------------+
2.5,5,7.5,10,12.5,15 |
SELECT a.id, CAST(to_char(WM_CONCAT(a.id)) AS number) FROM WM_CONCAT_TEST a GROUP BY a.id;
ID|CAST(TO_CHAR(WM_CONCAT(A.ID))ASNUMBER)|
--+--------------------------------------+
1| 1|
2| 2|
3| 3|
4| 4|
5| 5|
6| 6|
SELECT WM_CONCAT(CAST(to_char((a.id/2+a.id*2)) AS number)) FROM WM_CONCAT_TEST a GROUP BY a.id;
WM_CONCAT(CAST(TO_CHAR((A.ID/2+A.ID*2))ASNUMBER))|
-------------------------------------------------+
2.5 |
5 |
7.5 |
10 |
12.5 |
15 |
-- 转换后GaussDB-Oracle SQL:
CREATE TABLE wm_concat_test (id number,name varchar2(100),department varchar2(100));
INSERT INTO wm_concat_test (id,name,department) VALUES (1,'John','IT');
INSERT INTO wm_concat_test (id,name,department) VALUES (2,'Jane','HR');
INSERT INTO wm_concat_test (id,name,department) VALUES (3,'Tom','IT');
INSERT INTO wm_concat_test (id,name,department) VALUES (4,'Alice','Finance');
INSERT INTO wm_concat_test (id,name,department) VALUES (5,'Bob','IT');
INSERT INTO wm_concat_test (id,name,department) VALUES (6,'Mary','HR');
SELECT string_agg('', ',') FROM WM_CONCAT_TEST AS a;
string_agg|
----------+
|
SELECT string_agg(NULL, ',') FROM WM_CONCAT_TEST AS a;
string_agg|
----------+
|
SELECT string_agg(a.name, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
----------------------------+
John,Jane,Tom,Alice,Bob,Mary|
SELECT string_agg(DISTINCT a.name, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
----------------------------+
Alice,Bob,Jane,John,Mary,Tom|
SELECT string_agg(((a.name||':')||a.name), ',') FROM WM_CONCAT_TEST AS a;
string_agg |
---------------------------------------------------------+
John:John,Jane:Jane,Tom:Tom,Alice:Alice,Bob:Bob,Mary:Mary|
SELECT string_agg(((a.name||':')||a.id), ',') FROM WM_CONCAT_TEST AS a;
string_agg |
----------------------------------------+
John:1,Jane:2,Tom:3,Alice:4,Bob:5,Mary:6|
SELECT department,string_agg(a.name, ',') FROM wm_concat_test AS a GROUP BY a.department;
department|string_agg |
----------+------------+
Finance |Alice |
HR |Jane,Mary |
IT |John,Tom,Bob|
SELECT department,string_agg(a.name, ',') FROM wm_concat_test AS a GROUP BY a.department ORDER BY a.department;
department|string_agg |
----------+------------+
Finance |Alice |
HR |Jane,Mary |
IT |John,Tom,Bob|
SELECT department,string_agg(a.name, ',') FROM wm_concat_test AS a GROUP BY a.department ORDER BY a.department DESC;
department|string_agg |
----------+------------+
IT |John,Tom,Bob|
HR |Jane,Mary |
Finance |Alice |
SELECT string_agg(a.department, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
----------------------+
IT,HR,IT,Finance,IT,HR|
SELECT string_agg(DISTINCT a.department, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
-------------+
Finance,HR,IT|
SELECT string_agg(a.id+a.id, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
-------------+
2,4,6,8,10,12|
SELECT string_agg(a.id+a.id-1, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
------------+
1,3,5,7,9,11|
SELECT string_agg(a.id+a.id*2, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
--------------+
3,6,9,12,15,18|
SELECT string_agg(a.id/2+a.id*2, ',') FROM WM_CONCAT_TEST AS a;
string_agg |
----------------------------------------------------------------------------------------------------------------------------+
2.50000000000000000000,5.00000000000000000000,7.5000000000000000,10.0000000000000000,12.5000000000000000,15.0000000000000000|
SELECT a.id,CAST(to_char(string_agg(a.id, ',')) AS number) FROM WM_CONCAT_TEST AS a GROUP BY a.id;
id|to_char|
--+-------+
4| 4|
3| 3|
6| 6|
2| 2|
5| 5|
1| 1|
SELECT string_agg(CAST(to_char((a.id/2+a.id*2)) AS number), ',') FROM WM_CONCAT_TEST AS a GROUP BY a.id;
string_agg |
----------------------+
10.0000000000000000 |
7.5000000000000000 |
15.0000000000000000 |
5.00000000000000000000|
12.5000000000000000 |
2.50000000000000000000|
1.3.2.2.9.9. 分析函数
1.3.2.2.9.9.1. PERCENTILE_CONT
语法
PERCENTILE_CONT(percentile) WITHIN GROUP (ORDER BY column [ DESC | ASC ]) OVER (PARTITION BY column)
注意
该窗口函数不能嵌套使用,且窗口函数中不能用表达式,只能用具体的字段列,不能是字面量,字段列必须有表别名前缀;
窗口函数PARTITION BY 中只能有一个列字段;
查询中有多个PERCENTILE_CONT窗口函数时,每个PARTITION BY 中字段必须相同
只能在select中使用,且当前查询from中不能用关联查询只能用单表或者子查询,不能用虚拟表;
只能在同层select使用不能跨层使用
当前查询的窗口函数需要有别名,窗口函数中的字段需要有表名前缀,对应的查询的表必须有表别名,且查询的列必须带上表别名;
SELECT 中不能有其他窗口函数,聚合函数
子查询不能嵌套超过三层
示例
create table unisql_sales
(
EMPNO NUMBER(4) not null,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (1, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800.00, null, 20);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (2, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600.00, 300.00, 30);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (3, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250.00, 500.00, 30);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (4, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975.00, null, 20);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (5, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250.00, 1400.00, 30);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (6, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850.00, null, 30);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450.00, null, 10);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (8, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000.00, null, 20);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (9, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000.00, null, 10);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (10, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500.00, 0.00, 30);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (11, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100.00, null, 20);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (12, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950.00, null, 30);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (13, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000.00, null, 20);
insert into unisql_sales (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (14, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300.00, null, 10);
-- 转换前Oracle SQL:
select e.ename,e.sal,e.deptno,
PERCENTILE_CONT(0) within group(order by e.sal desc)
over(partition by e.deptno) max_sal ,
PERCENTILE_CONT(0.25) within group(order by e.sal desc)
over(partition by e.deptno) max_sal_25,
PERCENTILE_CONT(0.5) within group(order by e.sal desc)
over(partition by e.deptno) max_sal_50,
PERCENTILE_CONT(0.75) within group(order by e.sal desc)
over(partition by e.deptno) max_sal_75
from unisql_sales e ORDER BY e.EMPNO;
ENAME |SAL |DEPTNO|MAX_SAL|MAX_SAL_25|MAX_SAL_50|MAX_SAL_75|
------+----+------+-------+----------+----------+----------+
SMITH | 800| 20| 3000| 3000| 2975| 1100|
ALLEN |1600| 30| 2850| 1575| 1375| 1250|
WARD |1250| 30| 2850| 1575| 1375| 1250|
JONES |2975| 20| 3000| 3000| 2975| 1100|
MARTIN|1250| 30| 2850| 1575| 1375| 1250|
BLAKE |2850| 30| 2850| 1575| 1375| 1250|
CLARK |2450| 10| 5000| 3725| 2450| 1875|
SCOTT |3000| 20| 3000| 3000| 2975| 1100|
KING |5000| 10| 5000| 3725| 2450| 1875|
TURNER|1500| 30| 2850| 1575| 1375| 1250|
ADAMS |1100| 20| 3000| 3000| 2975| 1100|
JAMES | 950| 30| 2850| 1575| 1375| 1250|
FORD |3000| 20| 3000| 3000| 2975| 1100|
MILLER|1300| 10| 5000| 3725| 2450| 1875|
-- 转换后GaussDB-Oracle SQL:
SELECT e.ename,e.sal,e.deptno,
unisql_right_1105042549.max_sal AS max_sal,
unisql_right_1105042549.max_sal_25 AS max_sal_25,
unisql_right_1105042549.max_sal_50 AS max_sal_50,
unisql_right_1105042549.max_sal_75 AS max_sal_75
FROM unisql_sales AS e
JOIN (SELECT e.deptno,
PERCENTILE_CONT(0) WITHIN GROUP (ORDER BY e.sal DESC) AS max_sal,
PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY e.sal DESC) AS max_sal_25,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY e.sal DESC) AS max_sal_50,
PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY e.sal DESC) AS max_sal_75
FROM unisql_sales AS e GROUP BY e.deptno) AS unisql_right_1105042549
ON e.deptno=unisql_right_1105042549.deptno
ORDER BY e.EMPNO
ename |sal |deptno|max_sal|max_sal_25|max_sal_50|max_sal_75|
------+-------+------+-------+----------+----------+----------+
SMITH | 800.00| 20| 3000.0| 3000.0| 2975.0| 1100.0|
ALLEN |1600.00| 30| 2850.0| 1575.0| 1375.0| 1250.0|
WARD |1250.00| 30| 2850.0| 1575.0| 1375.0| 1250.0|
JONES |2975.00| 20| 3000.0| 3000.0| 2975.0| 1100.0|
MARTIN|1250.00| 30| 2850.0| 1575.0| 1375.0| 1250.0|
BLAKE |2850.00| 30| 2850.0| 1575.0| 1375.0| 1250.0|
CLARK |2450.00| 10| 5000.0| 3725.0| 2450.0| 1875.0|
SCOTT |3000.00| 20| 3000.0| 3000.0| 2975.0| 1100.0|
KING |5000.00| 10| 5000.0| 3725.0| 2450.0| 1875.0|
TURNER|1500.00| 30| 2850.0| 1575.0| 1375.0| 1250.0|
ADAMS |1100.00| 20| 3000.0| 3000.0| 2975.0| 1100.0|
JAMES | 950.00| 30| 2850.0| 1575.0| 1375.0| 1250.0|
FORD |3000.00| 20| 3000.0| 3000.0| 2975.0| 1100.0|
MILLER|1300.00| 10| 5000.0| 3725.0| 2450.0| 1875.0|