本章节为使用者提供最简单的统一SQL的快速入门。
1.2.1. 在线验证
可以通过 统一SQL在线转换 来快速验证当前统一SQL已支持的功能。
1.2.2. 使用LightDB-Studio验证
LightDB-Studio是一款数据库客户端工具,详细介绍可参考 LightDB Studio 参考手册 ,目前LightDB-Studio已经支持集成统一SQL,集成之后用户可以直接在LightDB-Studio中编写和执行SQL语句,LightDB-Studio会根据你配置的统一SQL信息将SQL语法转换为目标数据库语句并在目标库执行,用户可以看到转换后的SQL语法及目标端执行结果。下面会按照
集成统一SQL,创建统一SQL数据源,验证依次介绍如何使用LightDB-Studio集成统一SQL并验证。
1.2.2.1. 集成统一SQL
首先 点击下载 最新版的 LightDB-Studio 客户端工具到本地。
创建
统一SQL驱动管理器,用于管理统一SQL自有驱动及目标端数据库所依赖的驱动信息。打开LightDB-Studio,点击菜单栏数据库->驱动管理器->新建,配置统一SQL驱动管理器信息。内容填写参考表格:
填写项 |
说明 |
驱动名称 |
用户自定义,例如: |
驱动类型 |
选择Generic |
类名 |
填写: |
URL模版 |
不同转换数据源模版配置有所差异,具体可查看 数据库支持范围 表格中 |
默认端口 |
操作目标端数据库端口号,非必填项,默认端口号可根据实际情况填写。 |
默认数据库 |
操作目标端数据库名称,非必填项,默认数据库名称可根据实际情况填写。 |
默认用户名 |
操作目标端数据库用户名,非必填项,默认用户名可根据实际情况填写。 |
其他填写项按默认值即可。
例如,添加oracle->DM 数据库的驱动管理器:
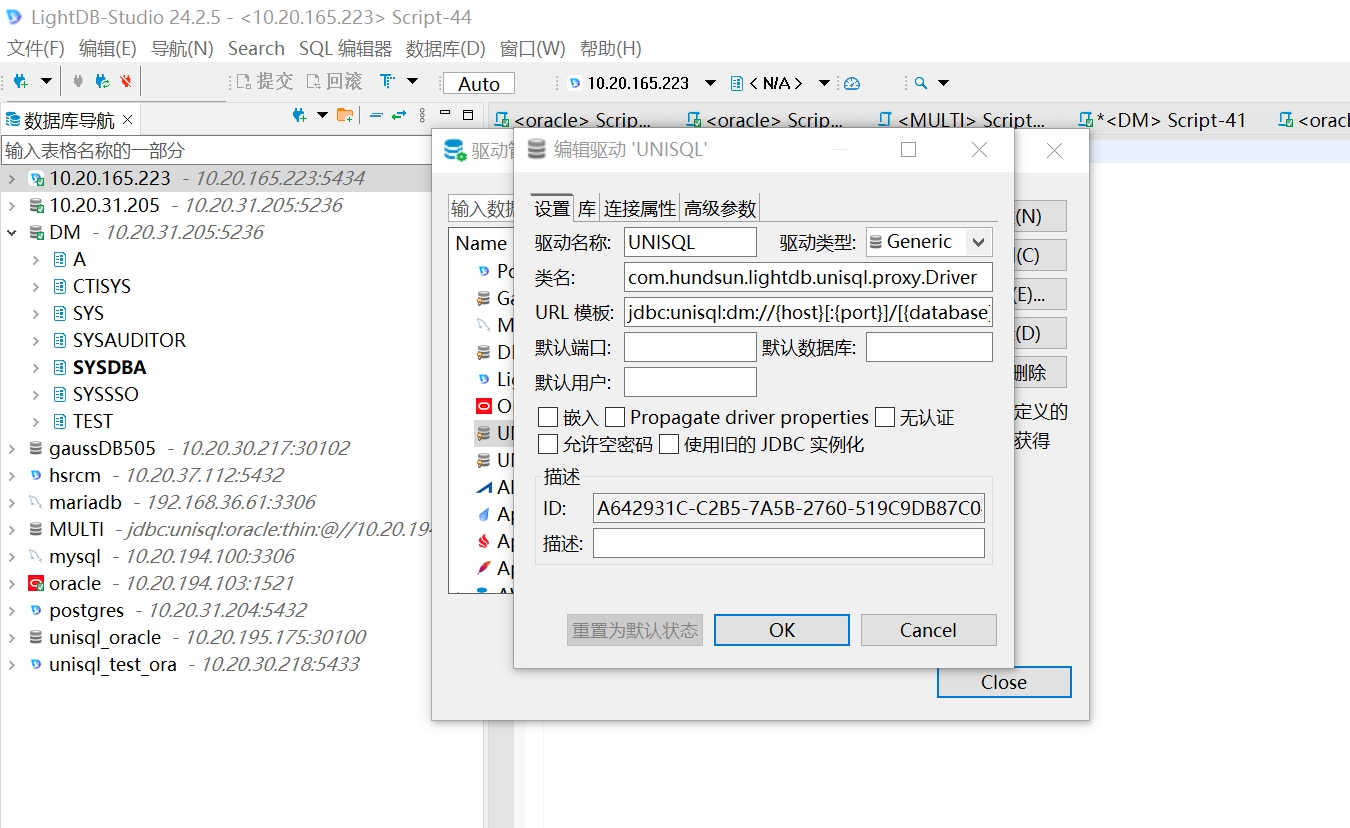
点击
库,添加统一SQL依赖驱动包及目标端数据库驱动包,其中目标端数据库驱动包根据实际操作的目标数据库选择添加,添加方式与统一SQL依赖驱动包添加方式一致。点击添加文件或添加文件夹按钮,选择sql-convert-runtime-x.x.x.jar文件,点击OK按钮完成添加。依赖包文件可在 统一SQL下载页面 中LightDB中间件->统一SQL->下载(动态库)下载,下载之后完成解压,找到sql-convert-runtime-x.x.x.jar文件。例如,添加统一SQL依赖及DM数据库驱动依赖:
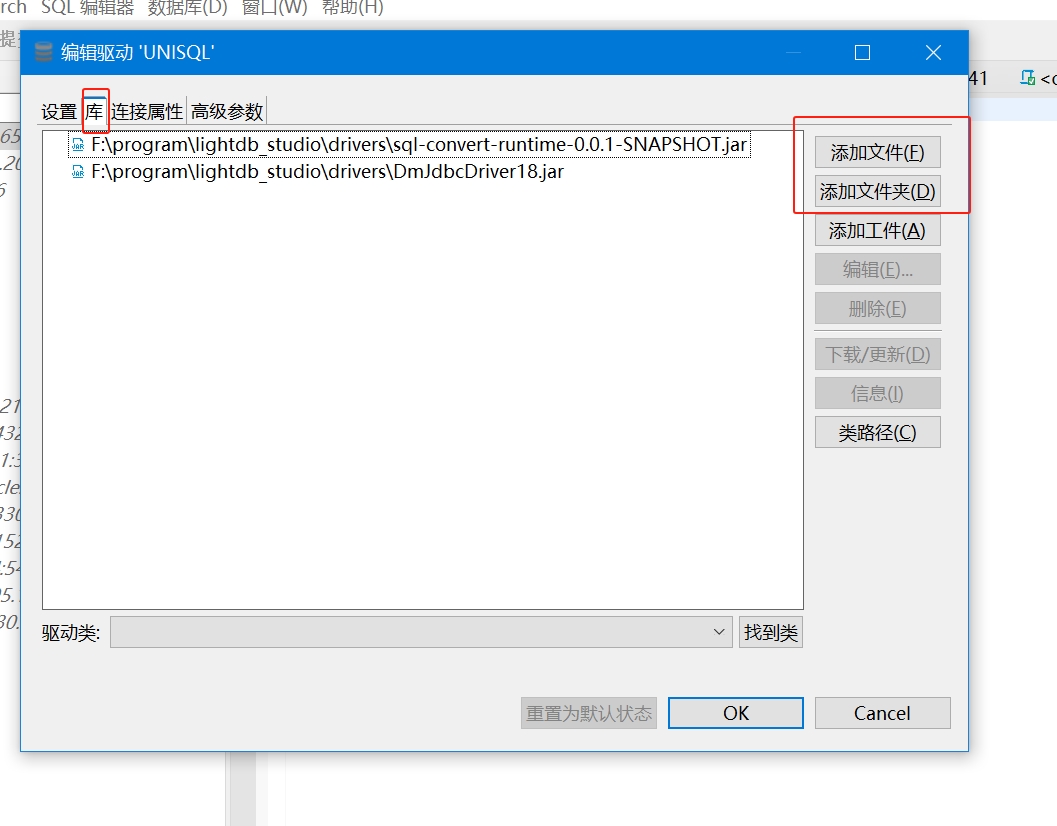
LightDB-Studio 配置统一SQL动态库。
将下载的
统一SQL依赖包中的config文件夹拷贝到本地lightdb-studio安装目录下。将下载的
统一SQL依赖包中的动态库文件拷贝到LightDB-Studio安装目录下的config文件夹中,如果是windows系统,动态库可以在 统一SQL下载页面 中 的LightDB中间件->统一SQL->windows版(仅用于开发)下载。打开LightDB-Studio安装目录下的
config/unisql.conf文件,配置unisql.lib.full-path项,值为动态库所在绝对路径(此配置方法适用于统一SQL大于等于24.2.6版本), 其他配置项可以参考: unisql.conf文件说明。例如:
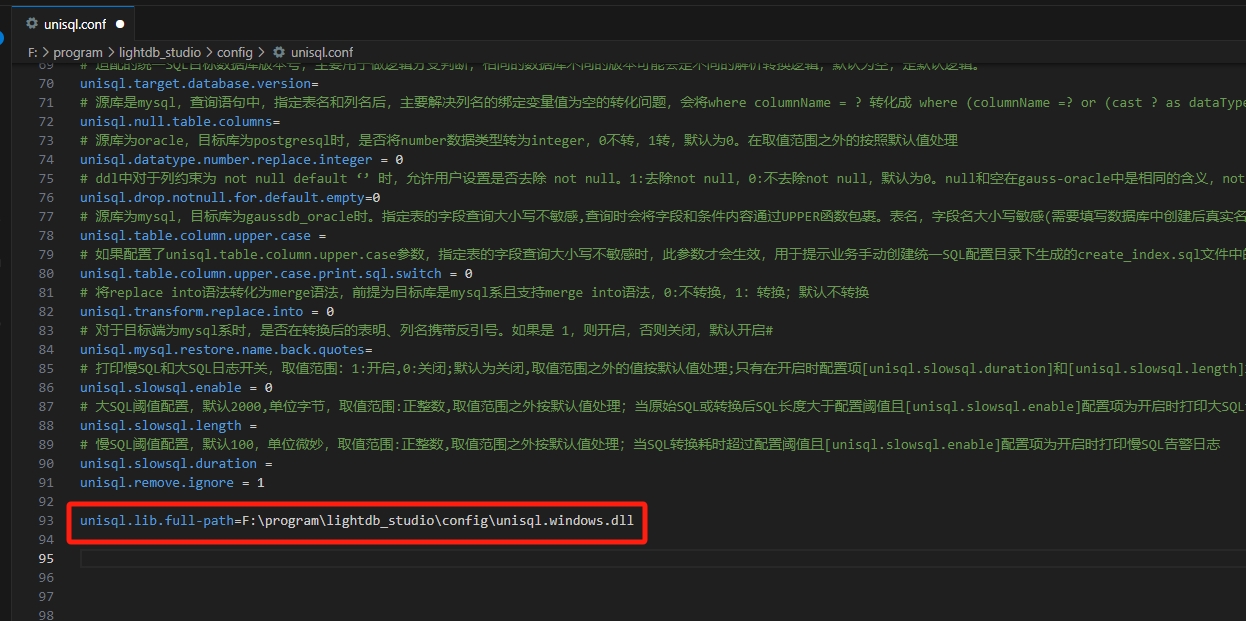
1.2.2.2. 创建统一SQL数据源
点击LightDB-Studio菜单栏
新建数据库连接选择刚刚创建的
数据库驱动管理器例如:
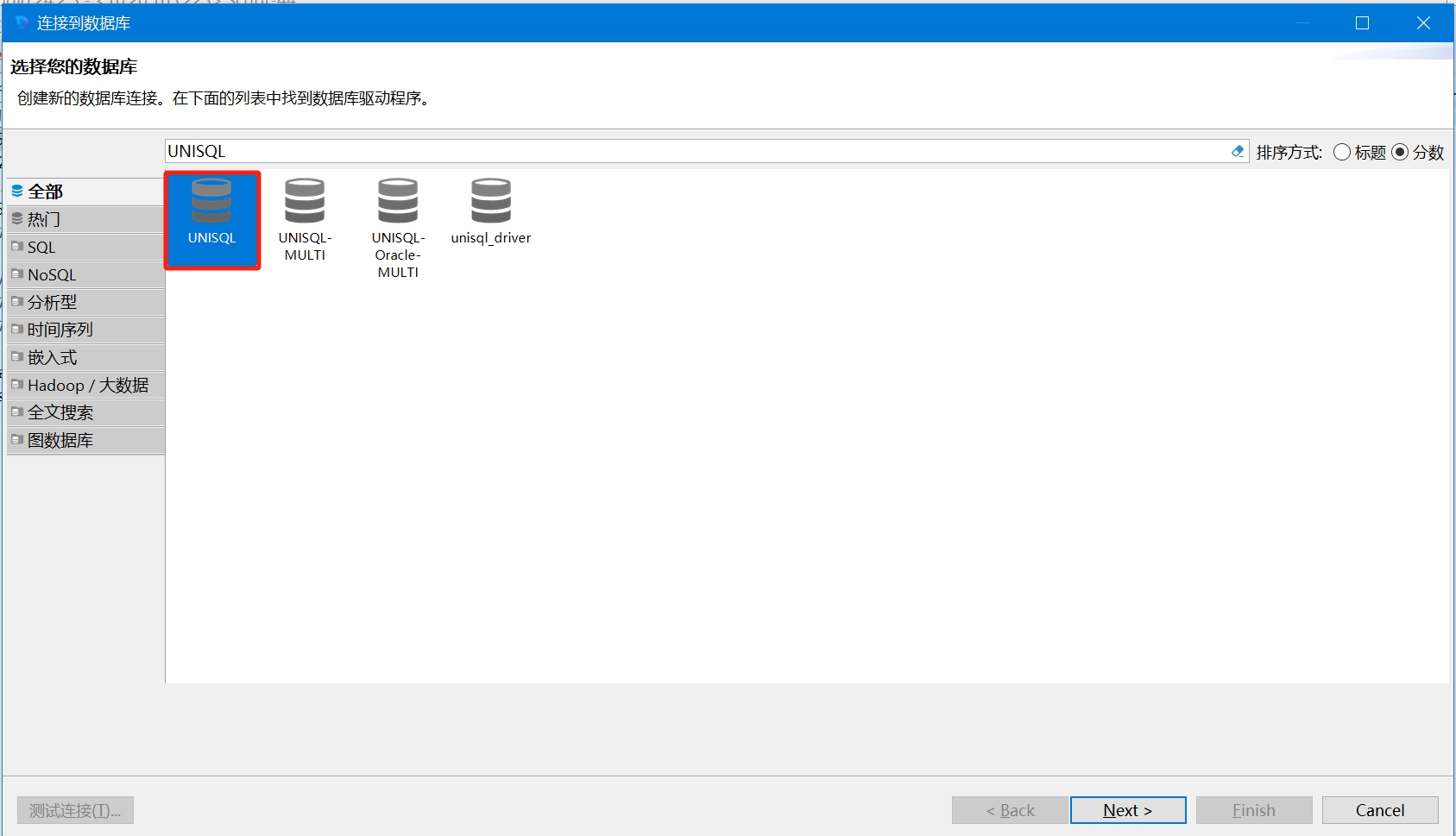
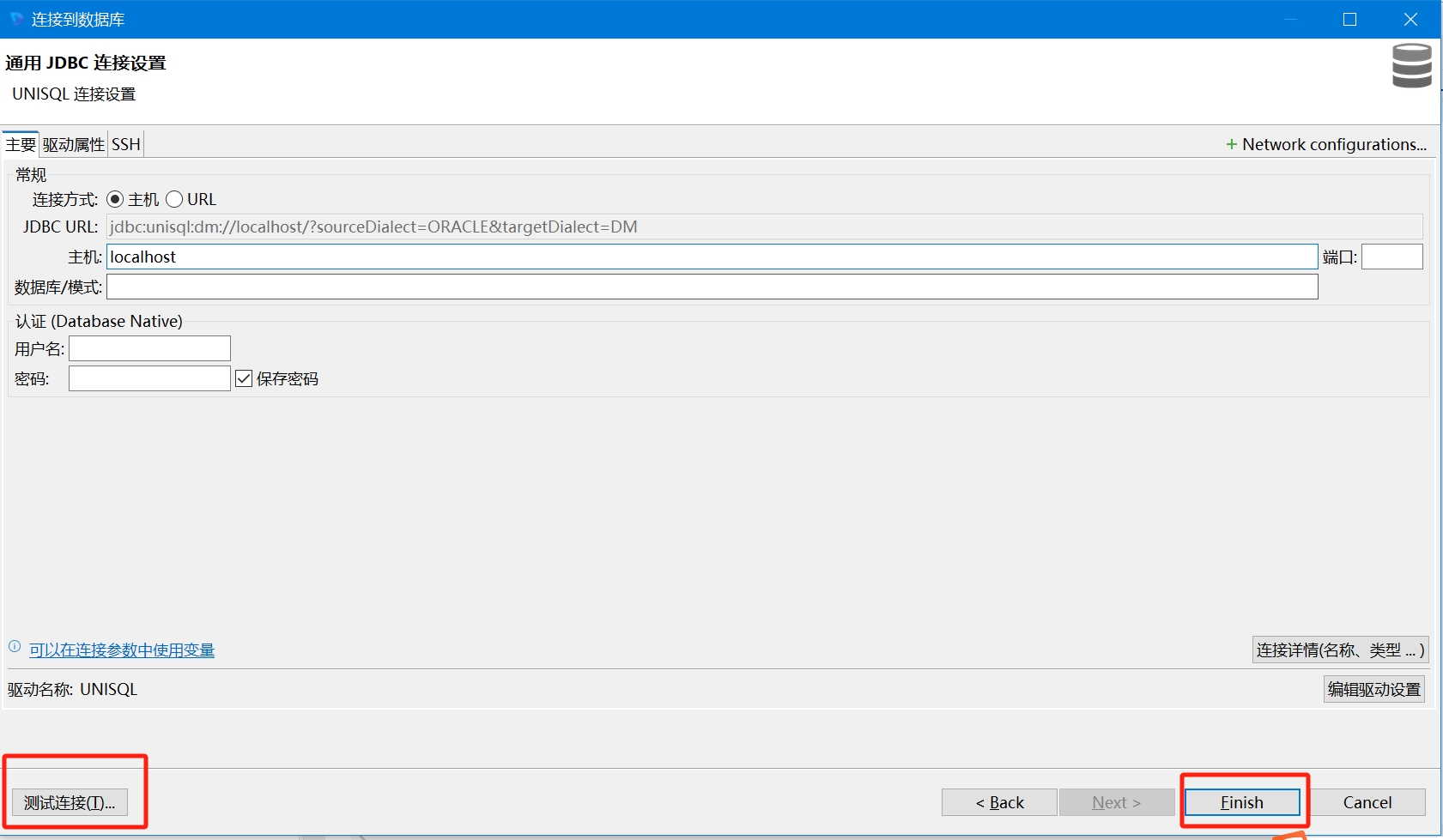
填写目标数据库信息,包括IP地址、端口号、数据库名称、用户名、密码等。可以点击
测试连接按钮测试连接是否成功。点击finish完成配置。例如:
1.2.2.3. 验证
选中上一步创建的数据库,右击选择
SQL编辑器->新建SQL编辑器,输入源端SQL语法语句并执行。此时操作的SQL语句会经过统一SQL转换为目标端语法并在目标端数据库中执行。
1.2.3. 支持技术栈
统一SQL当前支持集成在Java技术栈和C技术栈中使用
Java 技术栈支持 JDK 8 17 版本
1.2.4. 快速集成
1.2.4.1. 集成前提
在LightDB官网下载统一SQL 下载
基于Java开发时,开发环境需要具备 Java 8 或更高版本的 JDK。
确定源库方言和目标库方言在统一SQL支持范围内。
统一SQL自身依赖的自定义函数需要提前在目标库中完成创建,创建方式可以参考:导入统一SQL脚本到目标库中。
统一SQL代理维护在公司仓库中,需要提前联系统一SQL产品组配置仓库地址。
请确保引入最新的
sql-convert-runtime和sql-convert-runtime-native版本,否则可能存在兼容性或引入失败问题。最新版本可查看 版本发布 25.4.0.5对于统一SQL Windows 版 SDK,其版本号必须和
sql-convert-runtime版本号匹配,否则会启动失败。
1.2.4.2. 集成统一SQL代理
统一SQL代理是标准的Maven依赖,直接通过 pom.xml 配置即可。C技术栈集成时无需此步骤。
<dependency> <groupId>com.hundsun.lightdb</groupId> <artifactId>sql-convert-runtime</artifactId> <version>${version}</version> </dependency>统一SQL版本号:
${version}请参考 版本发布 25.4.0.5 。
1.2.4.3. 集成统一SQL SDK
1.2.4.4. Linux系统集成
Linux版统一SQL SDK是标准的Maven依赖,直接通过 pom.xml 配置即可。
<dependency> <groupId>com.hundsun.lightdb</groupId> <artifactId>sql-convert-runtime-native</artifactId> <version>${version}</version> <classifier>linux</classifier> </dependency>统一SQL版本号:
${version}请参考 版本发布 25.4.0.5 。也可以通过 unisql.conf 配置文件中的
unisql.lib.full-path=/xxx/xxx/unisql.linux.x86_64.so来指定统一SQL SDK所在绝对路径。 或者unisql.lib.dir=/path/to/来指定统一SQL SDK所在目录。(动态库寻找优先级:unisql.lib.full-path > Maven 依赖 > unisql.lib.dir)具体使用方法可参考 配置文件 。
1.2.4.5. Windows系统集成
获取统一SQL Windows版SDK ,从25.4.0开始提供标准的Maven依赖,可直接通过 pom.xml 进行配置,该方式无需执行第三步手动配置链接库路径。
<dependency> <groupId>com.hundsun.lightdb</groupId> <artifactId>sql-convert-runtime-native</artifactId> <version>${version}</version> <classifier>windows</classifier> </dependency>统一SQL版本号:
${version}请参考 版本发布 25.4.0.5 。Java程序启动时,通过 unisql.conf配置文件中的
unisql.lib.full-path=/path/to/unisql.windows.dll的方式进行集成。具体使用方法可参考 配置文件 。在Windows平台下
TransferSQL函数不支持
警告
仅支持 Windows 10 及更高版本或 Windows Server 2016 及更高版本。
1.2.4.6. C技术栈集成
C 技术栈的程序要使用统一 SQL 的功能,只需要按照您项目的规范,正确引用 unisql.h 与 libunisql.so 即可。
一种典型的步骤为:
配置编译器参数
-L path_to_unisql/lib -l unisql,使程序在链接阶段能够找到统一 SQL 动态库配置编译器参数
-I path_to_unisql/include,使程序能够处理#include "unisql.h"和#include "unisql_dbtype.h"运行程序前,将
path_to_unisql/lib配置在 LD_LIBRARY_PATH 中,使程序运行时能够找到统一 SQL 动态库
C 技术栈集成统一 SQL 时,同样能够使用配置文件。具体使用方法可参考 配置文件 。
在后续章节也有使用 C API 的例子,参考 调用示例 。
1.2.4.7. 导入统一SQL脚本到目标库中
由于部分目标方言的特性缺失,统一SQL通过自定义数据库函数的方式来模拟源方言的功能,需要用户将该部分脚本导入到目标库中。SQL脚本包含在官网制品中的 LightDB1.0-unisql-Vxxxxxx-xx-xxx 包下的sql 目录下,包含各个版本的增量脚本和 all 目录下的全量脚本。
1.2.4.7.1. 统一SQL脚本升级工具
统一SQL自定义对象脚本可以通过升级工具进行执行,打入目标数据库。建议使用超级用户执行,或者通过具有 CREATE 、EXECUTE、GRANT、SELECT、UPDATE、INSERT权限的用户来执行。 unisql-upgrade-<version>.jar 升级工具jar包位于sql 目录下。执行日志生成在logs 目录下的unisql-upgrade.log文件中。
具体使用方法,如下示例:
java -jar unisql-upgrade-25.4.0.jar --help
Usage:
java -jar unisql-upgrade-<version>.jar -S 源端数据库类型 -T 目标端数据库类型 -h 数据库IP -p 数据库端口 -U 数据库用户名 -W 数据库密码 -d 要连接的数据库名称 [-all] [OPTION]...
options:
-S, --source ,是否必须:是, 源端数据库类型(ORACLE、MYSQL)
-T, --target ,是否必须:是, 目标端数据库类型(当源为ORACLE时,目标库取值范围:POSTGRESQL、TDSQL_MYSQL、OCEAN_BASE_MYSQL、TDSQL_PG_ORACLE、GAUSSDB_ORACLE、TDSQL_PG、GOLDENDB_MYSQL;当源为MYSQL时,目标库取值范围:GAUSSDB500_ORACLE、ORACLE_19C、OCEAN_BASE_ORACLE、GAUSSDB_ORACLE、GAUSSDB_MYSQL_B、TDSQL_PG、DM)
-h, --host ,是否必须:是, 数据库IP
-p, --port ,是否必须:是, 数据库端口
-U, --username ,是否必须:是, 数据库用户名
-W, --password ,是否必须:是, 数据库密码
-d, --dbname ,是否必须:是, 要连接的数据库名称。(暂不支持大小写敏感)
-s, --schema ,是否必须:否, 将sql脚本打入到哪个schema(TDSQL_MYSQL、OCEAN_BASE_MYSQL则为database)下(默认: unisql )。暂不支持大小写敏感
-v, --version ,是否必须:否, 升级到指定版本(版本号见官网的版本发布历史章节,格式:xx(年份).xx(RP版本).xx(增量版本).xxx(补丁版本)。默认为当前安装包最新版本)
-all, --all ,是否必须:否, 是否执行全量脚本选项,具有最高优先级(高于-v),第一次接入时可以选择执行全量脚本,否则进行增量脚本的迭代升级
-help, --help 显示 jar 命令的用法和所有可用的选项
警告
业务使用的用户或后续新增的用户,需要确保有访问database和schema的权限。
TDSQL_MYSQL、OCEAN_BASE_MYSQL、GOLDENDB_MYSQL新增用户后,需要为新用户分配统一SQL数据库的函数执行权限。分配方法如下,需要root用户来执行:call unisql.GrantUnisqlPermissions();如果初始化时指定了非unisql数据库。则call 指定的数据库.GrantUnisqlPermissions();TDSQL_MYSQL连接需要用真实端口号,不要用代理端口号。统一sql依赖的自定义对象默认创建在 unisql 的schema下(目标库为TDSQL_MYSQL、OCEAN_BASE_MYSQL则为unisql数据库)。
如果想创建在指定的schema (TDSQL_MYSQL、OCEAN_BASE_MYSQL则为database)可以使用脚本升级工具的
--schema参数指定(后续升级时也需要和第一次设置时相同,同时统一SQL配置文件unisql.conf中unisql.schema配置项也需要同步变更为指定的schema或database)。全量脚本可以通过-all选项执行。
增量脚本升级前提,schema/database已存在且有执行权限
如果是24.2.6版本之前用户,第一次使用升级工具且是增量执行时,需要手动维护统一SQL版本信息表到指定的schema(TDSQL_MYSQL、OCEAN_BASE_MYSQL则为database)下(默认是unisql),具体脚本见如下各个源端到目标端的脚本。
输出日志编码格式为UTF-8
用户名、密码、schema不支持中文,如果中间有空格用双引号包裹(内容两边双引号会被识别去除,因此本身内容不支持双引号)
环境必须要有jre(java version>=1.8)
如果是24.2.6版本之前用户,第一次使用升级工具且是增量执行时,需要手动维护统一SQL版本信息表到指定的schema下(默认是unisql),版本号为
xx(年份).xx(RP版本).xx(增量版本).xxx(补丁版本)见版本发布历史章节。 需要填写升级前使用的实际版本号。
1.2.4.8. 在项目中使用统一SQL
1.2.4.8.1. 直接调用统一SQL的转换API
统一SQL代理暴露了转换API,用户可以直接调用该API完成统一SQL转换,方法说明如下:
统一SQL转换 public static String parse(String sql, String source, String target)说明:
sql源方言SQL语句,表示需要转换的SQL语句;
source源方言,当前支持oracle和mysql;
target目标方言,参见SQL参考
返回值转换后SQL统一SQL转换 public static String parse(String sql, String source, String target, long sessionId)说明:
sql源方言SQL语句,表示需要转换的SQL语句;
source源方言,当前支持oracle和mysql;
target目标方言,参见SQL参考
sessionId会话ID
返回值转换后SQL设置会话级别参数 public static void setSessionParamStr(String paramName, String paramValue, long sessionId)说明:
paramName参数名称
paramValue参数值
sessionId会话ID创建统一SQL会话 public static Long createSession()说明:
返回值会话ID销毁统一SQL会话 public static void freeSession(Long sessionId)注意:
sessionId会话ID示例代码
@Test public void testTransform(){ // 源SQL语句 String sql = "select client_id as inner_client_id, client_id, EXTRACT(DAY FROM to_timestamp(to_char(20230823),'yyyymmdd')-to_timestamp(to_char(id_end_date),'yyyymmdd')) as remarks from hsamlbd.amlbd_ins_client where client_type in ('1','2') and to_date(id_end_date,'yyyymmdd') < to_date(20230823,'yyyymmdd') and id_end_date <> '19000101'"; // 源方言 String sourceDialect = DbType.ORACLE.name(); // 目标方言 String targetDialect = DbType.POSTGRESQL.name(); System.out.printf("Before transfer sql is:%s \n",sql); String parse = Transformer.parse(sql, sourceDialect,targetDialect ); System.out.printf("After transfer sql is:%s \n",parse); } // 运行结果 Before transfer sql is:select client_id as inner_client_id, client_id, EXTRACT(DAY FROM to_timestamp(to_char(20230823),'yyyymmdd')-to_timestamp(to_char(id_end_date),'yyyymmdd')) as remarks from hsamlbd.amlbd_ins_client where client_type in ('1','2') and to_date(id_end_date,'yyyymmdd') < to_date(20230823,'yyyymmdd') and id_end_date <> '19000101' Aefore transfer sql is:SELECT client_id AS inner_client_id,client_id,EXTRACT(DAY FROM to_timestamp(CAST(20230823 AS text), 'yyyymmdd')-to_timestamp(CAST(id_end_date AS text), 'yyyymmdd')) AS remarks FROM hsamlbd.amlbd_ins_client WHERE client_type IN ('1','2') AND CAST(to_timestamp(id_end_date, 'yyyymmdd') AS timestamp)<CAST(to_timestamp(20230823, 'yyyymmdd') AS timestamp) AND id_end_date<>'19000101'示例代码 会话级别转换(修改参数仅在当前会话生效)
@Test public void sesssionParseTest() { // 源SQL语句 String sql = "select 1 from dual;"; Long sessionId = Transformer.createSession(); Transformer.setSessionParamStr("unisql.skip", "true", sessionId); System.out.printf("Before transfer sql is:%s \n",sql); String parse1 = Transformer.parse(sql, DbType.ORACLE.name(), DbType.POSTGRESQL.name(), sessionId); System.out.printf("After transfer sql is:%s \n",parse1); Transformer.freeSession(sessionId); System.out.printf("Before transfer sql is:%s \n",sql); String parse2 = Transformer.parse(sql, DbType.ORACLE.name(), DbType.POSTGRESQL.name()); System.out.printf("After transfer sql is:%s \n",parse2); System.out.println(parse2); } // 运行结果 Before transfer sql is:select 1 from dual; After transfer sql is: select 1 from dual; Before transfer sql is:select 1 from dual; After transfer sql is: SELECT 1;
1.2.4.8.2. 通过原生JDBC的方式使用
注意:
jdbc url必须以jdbc:unisql:开头,表示使用统一SQL代理;连接参数中的
sourceDialect表示源方言,以下示例是oracle;连接参数中的
targetDialect表示目标方言,以下示例是postgresql;public static final String URL = "jdbc:unisql:postgresql://10.20.30.40:5432/test?sourceDialect=oracle&targetDialect=postgresql"; public static final String USER = "user"; public static final String PASSWORD = "password"; @Test void testJdbc() { try { Class.forName("org.postgresql.Driver"); Class.forName("com.hundsun.lightdb.unisql.proxy.Driver"); Connection conn = DriverManager.getConnection(URL, USER, PASSWORD); Statement stmt = conn.createStatement(); // 原生oracle sql语句 String oracleSQL = "select nation, listagg(city, ',') within GROUP (order by city1, city2 desc) from temp group by nation"; // 返回postgresql执行结果 ResultSet rs = stmt.executeQuery(oracleSQL); while (rs.next()) { System.out.println(rs.getString("nation")); } conn.close(); } catch (Exception e) { throw new RuntimeException(e); } } @Test void testJdbcPrepareStatement() { try { Class.forName("org.postgresql.Driver"); Class.forName("com.hundsun.lightdb.unisql.proxy.Driver"); Connection conn = DriverManager.getConnection(URL, USER, PASSWORD); Random random = new Random(); PreparedStatement pstmt = conn.prepareStatement("insert into t(col) values (?)"); int i = random.nextInt(); pstmt.setInt(1, i); Statement stmt = conn.createStatement(); pstmt.executeUpdate(); log.info("开始随机向t表插入:{}", i); conn.close(); } catch (Exception e) { throw new RuntimeException(e); } }
1.2.4.8.3. 基于JRESCloud3.X开发框架 + JdbcTemplate使用
如何集成jrescloud微服务可参考 微服务开发手册
配置统一SQL数据源
spring.datasource.driver-class-name=com.hundsun.lightdb.unisql.proxy.Driver spring.datasource.url=jdbc:unisql:postgresql://10.20.30.40:5432/test?sourceDialect=oracle&targetDialect=postgresql spring.datasource.username=user spring.datasource.password=password通过JdbcTemplate使用统一SQL
@Autowired JdbcTemplate jdbcTemplate; @Test void testSpringboot() { // 原生oracle sql语句 String oracleSQL = "select nation, listagg(city, ',') within GROUP (order by city1, city2 desc) from temp group by nation"; // 返回postgresql执行结果 List<Map<String, Object>> list = jdbcTemplate.queryForList(oracleSQL); }
1.2.4.8.4. 基于JRESCloud3.X开发框架 + mybatis + 多数据源使用
如何集成jrescloud微服务可参考 微服务开发手册
根据手册集成多数据源依赖
<dependency> <groupId>com.hundsun.jrescloud.middleware</groupId> <artifactId>jrescloud-starter-mybatis</artifactId> </dependency>
使用多数据源注解@EnableCloudDataSource开启多数据源
/** * 多数据源注解@EnableCloudDataSource,开启多数据源功能 */ @EnableCloudDataSource @CloudApplication // 启动类注解 public class UnisqlMultiDataSourceApplication { public static void main(String[] args) { CloudBootstrap.run(UnisqlMultiDataSourceApplication.class, args); } }
配置多数据源并使用统一SQL格式的jdbcUrl
hs.druid.validationQuery=select 1 hs.datasource.default.driverClassName=org.postgresql.Driver hs.datasource.default.url=jdbc:postgresql://10.20.30.40:5432/test hs.datasource.default.username=user hs.datasource.default.password=password hs.datasource.mysql.driverClassName=com.mysql.jdbc.Driver hs.datasource.mysql.url=jdbc:mysql://10.20.30.40:3306/test?useSSL=false&serverTimezone=UTC hs.datasource.mysql.username=user hs.datasource.mysql.password=password hs.datasource.unisql.driverClassName=com.hundsun.lightdb.unisql.proxy.Driver hs.datasource.unisql.url=jdbc:unisql:postgresql://10.20.30.40:5432/test?sourceDialect=oracle&targetDialect=postgresql hs.datasource.unisql.username=user hs.datasource.unisql.password=password
使用数据源指定注解@TargetDataSource指定当前服务类或服务方法所使用的数据源
public interface TestMapper { @Select("SELECT nation,STRING_AGG(city, ',' ORDER BY city1,city2 DESC) FROM temp GROUP BY nation") List<Map<String, Object>> queryForList(); @TargetDataSource("unisql") // 指定数据源unisql,该数据源将会使用统一SQL @Select("select nation, listagg(city, ',') within GROUP (order by city1, city2 desc) from temp group by nation") List<Map> queryForListUsingUnisql(); @TargetDataSource("unisql") List<Map> queryListForUnisql(); }
基于mybatis,指定数据源unisql的mapper接口方法queryListForUnisql对应的SQL映射文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.unisql.multi.db.mapper.TestMapper"> <select id="queryListForUnisql" resultType="map"> select nation, listagg(city, ',') within GROUP (order by city1, city2 desc) from temp group by nation; </select> </mapper>
测试mapper接口方法,确定是否使用了统一SQL
@SpringBootTest public class UnisqlMybatisTest { @Autowired private TestMapper testMapper; @Test void testMybatisUnisql() { List<Map> list = testMapper.queryForListUsingUnisql(); Assert.isTrue(!CollectionUtils.isEmpty(list)); } @Test void testMybatisListUnisql() { List<Map> list = testMapper.queryListForUnisql(); Assert.isTrue(!CollectionUtils.isEmpty(list)); } }
1.2.4.8.5. C技术栈:通过引入统一SQL动态库头文件来使用统一SQL的API
#include <stdio.h> #include <string.h> #include <stdlib.h> #include "unisql.h" #include "unisql_dbtype.h" int main() { // 数据库类型见unisql.h // 原始SQL数据库类型 int sourceDbTypeCode=UNISQL_DBTYPE_ORACLE; // 目标SQL数据库类型 int targetDbTypeCode=UNISQL_DBTYPE_GAUSSDB_ORACLE; // 原始SQL char* sourceSqlStr="SELECT o.order_id, o.order_date, c.customer_name, c.city, o.amount FROM unisql_orders o JOIN unisql_customers c ON o.customer_id = c.customer_id and c.customer_id=? and c.city=?;"; // 目标SQL char* targetSqlStr=NULL; // 转换配置选项,预留扩展字段,目前传 NULL 即可 char* jsonParameter = NULL; // 转换结果 0表示成功,>0表示目标串长度不够,<0表示失败 int transRet=0; // 预设目标SQL的长度为原始SQL的4倍 int targetSqlStrLen = strlen(sourceSqlStr)*4; // 分配内存 targetSqlStr=(char*)malloc(targetSqlStrLen); printf("Before transfer sql is:%s\n",sourceSqlStr); // 调用TransferSQL转换函数 transRet = TransferSQL(sourceDbTypeCode, targetDbTypeCode, sourceSqlStr, targetSqlStr, targetSqlStrLen, jsonParameter); if (transRet>0){ // 预设目标SQL的长度不够,重新分配内存 targetSqlStr=(char*) realloc (targetSqlStr, transRet) ; transRet =TransferSQL (sourceDbTypeCode, targetDbTypeCode, sourceSqlStr, targetSqlStr, transRet, jsonParameter); } if(transRet == 0) { printf("After transfer sql is:%s\n",targetSqlStr); }else if(transRet < 0) { printf("SQL Convert Failed:%d\n",transRet); } // 释放内存 free(targetSqlStr); return 0; } // 运行结果 //Before transfer sql is:SELECT o.order_id, o.order_date, c.customer_name, c.city, o.amount FROM unisql_orders o JOIN unisql_customers c ON o.customer_id = c.customer_id and c.customer_id=? and c.city=?; //After transfer sql is:SELECT o.order_id,o.order_date,c.customer_name,c.city,o.amount FROM unisql_orders AS o JOIN unisql_customers AS c ON o.customer_id=c.customer_id AND c.customer_id=? AND c.city=? // 本样例main.c、libunisql.so、unisql.linux.x86_64.so 在同一目录下 // 编译加入 -ldl -I -L 指定动态库路径 // gcc main.c -o main -I./ -L./ -lunisql -ldlAPI 说明可参考 统一SQL C 接口 。
1.2.5. 离线转化工具
统一sql离线转化工具提供linux环境下sql文件批量转化功能,可以将指定文本中的sql语句块转换为目标数据库的sql语句并输出到指定目录,目前支持的转换范围可参考 统一SQL使用边界规范。离线工具可以在官网下载界面点击 下载 中 统一SQL -> 下载(动态库),下载完成解压后进入可以在bin文件夹下获取,
文件名称 unisql_cli.xxx 根据不同操作系统进行选择使用。
使用方法:
拷贝统一sql制品中的config文件夹到工具同级目录下,以使用uisql.conf配置转化相关参数;
执行
./unisql_cli.xxx -help查看帮助信息;生成目标端文件格式为:目标数据库类型-文件名.sql;
$ ./unisql_cli.x86_64 -help
Usage:
./unisql_cli -s 源端数据库类型 -t 目标端数据库类型 -sd 源文件目录 [-td 目标文件目录] [-es 转化失败则跳过当前文件后续sql的转化]
options:
-s, -source , 是否必须:是, 源端数据库类型(ORACLE、MYSQL)
-t, -target , 是否必须:是, 目标端数据库类型
(源为ORACLE可配置:LIGHTDB_ORACLE、POSTGRESQL、TDSQL_MYSQL、OCEAN_BASE_MYSQL、OCEAN_BASE_ORACLE、TDSQL_PG_ORACLE、GAUSSDB_ORACLE、DM
源为MYSQL可配置:GAUSSDB500_ORACLE、GOLDENDB_MYSQL),多个目标数据库类型之间用半角,分隔
-sd, -source directory, 是否必须:是, 源文件目录,多个目录之间用半角,分隔
-td, -target directory, 是否必须:否, 目标文件目录,不设置则同源文件目录
-es, -error skip , 是否必须:否, 转化失败则跳过当前文件后续sql的转化 可设置值:t/f (true/false) 默认:t
-help, -help , 是否必须:否,显示所有可用的选项
示例:将oracle数据库SQL脚本转换为gaussDB数据库
$ ./unisql_cli.x86_64 -s ORACLE -t GAUSSDB_ORACLE -sd /home/oracle/sql -td /home/gaussdb/sql -es t
转化过程所有信息请查看当前目录下的转化日志,每个文件转化失败会在目标目录下产生对应的error文件方便查看错误原因。
警告
离线转化工具只支持普通文本文件(.sql、.txt)转换;
请确保文件中的sql语句块由符号
/或者;结尾。
1.2.5.1. sqlplus 命令
离线转换工具中支持sqlplus命令,目前只支持oracle数据库到oceanbase_oracle。
用法范围
-- 打开变量替换功能
SET DEFINE ON;
-- 关闭变量替换功能
SET DEFINE OFF;
-- 打开程序输出
SET SERVEROUTPUT ON;
-- 关闭程序输出
SET SERVEROUTPUT OFF;
-- 提示
PROMPT Starting the script...
-- SPOOL输出重定向
SPOOL file_name[.ext]
-- 关闭 SPOOL 输出
SPOOL OFF;
-- 转换后oceanbase_oracle语法
SET DEFINE ON;
SET DEFINE OFF;
SET SERVEROUTPUT ON;
SET SERVEROUTPUT OFF;
PROMPT Starting the script...
TEE file_name[.ext]
NOTEE;
注意
目前只支持oceanbase_oracle目标库。
单次转换只支持单句语句。
oracle 重定向文件不带后缀时,生成的文件会默认带上.lst后缀,OCEAN_BASE_ORACLE则不会有后缀。
重定向一个文件,关闭重定向。多次重复重定向该文件oracle表现的是覆盖文件内容,而OCEAN_BASE_ORACLE是追加文件内容。
SPOOL 重定向文件名不支持特殊字符。