Platform Requirements
This topic describes the LightDB-A Database 6 platform and operating system software requirements for deploying the software to on-premise hardware, or to public cloud services such as AWS, GCP, or Azure.
On-Premise Hardware Requirements
This topic describes the LightDB-A Database 6 platform and operating system software requirements for deploying to on-premise hardware. It also provides important compatibility information for LightDB-A tools and extensions.
Operating Systems
LightDB-A Database 6 runs on the following operating system platforms:
- Red Hat Enterprise Linux 64-bit 8.7 or later
- Oracle Linux 64-bit 8.7 or later, using the Red Hat Compatible Kernel (RHCK)
- Rocky Linux 8.7 or later
Important A kernel issue in Red Hat Enterprise Linux 8.5 and 8.6 can cause I/O freezes and synchronization problems with XFS filesystems. This issue is fixed in RHEL 8.7. See RHEL8: xfs_buf deadlock between inode deletion and block allocation.
Note Do not install anti-virus software on LightDB-A Database hosts as the software might cause extra CPU and IO load that interferes with LightDB-A Database operations.
LightDB-A Database server supports TLS version 1.2 on RHEL/CentOS systems, and TLS version 1.3 on Ubuntu systems.
Software Dependencies
LightDB-A Database 7 requires the following software packages on RHEL systems. The packages are installed automatically as dependencies when you install the LightDB-A RPM package):
- apr
- apr-util
- bash
- bzip2
- curl
- krb5
- libcurl
- libevent
- libxml2
- libyaml
- zlib
- openldap
- openssh-client
- openssl
- openssl-libs (RHEL7/Centos7)
- perl
- readline
- rsync
- R
- sed (used by
gpinitsystem) - tar
- zip
VMware LightDB-A Database 7 client software requires these operating system packages:
- apr
- apr-util
- libyaml
- libevent
LightDB-A Database 7 uses Python 2.7.12, which is included with the product installation (and not installed as a package dependency).
Important SSL is supported only on the LightDB-A Database coordinator host system. It cannot be used on the segment host systems.
Important For all LightDB-A Database host systems, if SELinux is enabled in
Enforcingmode then the LightDB-A process and users can operate successfully in the defaultUnconfinedcontext. If increased confinement is required, then you must configure SELinux contexts, policies, and domains based on your security requirements, and test your configuration to ensure there is no functionality or performance impact to LightDB-A Database. Similarly, you should either deactivate or configure firewall software as needed to allow communication between LightDB-A hosts. See Deactivate or Configure SELinux.
Java
LightDB-A Databased 7 supports these Java versions for PL/Java and PXF:
- Open JDK 8 or Open JDK 11, available from AdoptOpenJDK
- Oracle JDK 8 or Oracle JDK 11
Hardware and Network
The following table lists minimum recommended specifications for hardware servers intended to support LightDB-A Database on Linux systems in a production environment. All host servers in your LightDB-A Database system must have the same hardware and software configuration. LightDB-A also provides hardware build guides for its certified hardware platforms. Work with a LightDB-A Systems Engineer to review your anticipated environment to ensure an appropriate hardware configuration for LightDB-A Database.
| Minimum CPU | Any x86_64 compatible CPU |
| Minimum Memory | 16 GB RAM per server |
| Disk Space Requirements |
|
| Network Requirements | 10 Gigabit Ethernet within the array NIC bonding is recommended when multiple interfaces are present LightDB-A Database can use either IPV4 or IPV6 protocols. |
Hyperthreading
Resource Groups - one of the key LightDB-A Database features - can control transaction concurrency, CPU and memory resources, workload isolation, and dynamic bursting.
When using resource groups to control resource allocation on Intel based systems, consider switching off Hyper-Threading (HT) in the server BIOS (for Intel cores the default is ON). Switching off HT might cause a small throughput reduction (less than 15%), but can achieve greater isolation between resource groups, and higher query performance with lower concurrency workloads.
VMware LightDB-A on DCA Systems
You must run VMware LightDB-A version 6.9 or later on Dell EMC DCA systems, with software version 4.2.0.0 and later.
Storage
The only file system supported for running LightDB-A Database is the XFS file system. All other file systems are explicitly not supported by VMware.
LightDB-A Database is supported on network or shared storage if the shared storage is presented as a block device to the servers running LightDB-A Database and the XFS file system is mounted on the block device. Network file systems are not supported. When using network or shared storage, LightDB-A Database mirroring must be used in the same way as with local storage, and no modifications may be made to the mirroring scheme or the recovery scheme of the segments.
Other features of the shared storage such as de-duplication and/or replication are not directly supported by LightDB-A Database, but may be used with support of the storage vendor as long as they do not interfere with the expected operation of LightDB-A Database at the discretion of VMware.
LightDB-A Database can be deployed to virtualized systems only if the storage is presented as block devices and the XFS file system is mounted for the storage of the segment directories.
LightDB-A Database is supported on Amazon Web Services (AWS) servers using either Amazon instance store (Amazon uses the volume names ephemeral[0-23]) or Amazon Elastic Block Store (Amazon EBS) storage. If using Amazon EBS storage the storage should be RAID of Amazon EBS volumes and mounted with the XFS file system for it to be a supported configuration.
Data Domain Boost (VMware LightDB-A)
VMware LightDB-A 6 supports Data Domain Boost for backup on Red Hat Enterprise Linux. This table lists the versions of Data Domain Boost SDK and DDOS supported by VMware LightDB-A 6.
| VMware LightDB-A | Data Domain Boost | DDOS |
|---|---|---|
| 6.x | 3.3 | 6.1 (all versions), 6.0 (all versions) |
Note In addition to the DDOS versions listed in the previous table, VMware LightDB-A supports all minor patch releases (fourth digit releases) later than the certified version.
VMware LightDB-A Tools and Extensions Compatibility
- Client Tools (VMware LightDB-A)
- Extensions
- Data Connectors
- VMware LightDB-A Text
- LightDB-A Command Center
Client Tools
VMware releases a Clients tool package on various platforms that can be used to access LightDB-A Database from a client system. The LightDB-A 7 Clients tool package is supported on the following platforms:
- Red Hat Enterprise Linux x86_64 8.x (RHEL 8)
- Oracle Linux 64-bit 8, using the Red Hat Compatible Kernel (RHCK)
- Rocky Linux 8
- Windows 10 (64-bit)
- Windows 8 (64-bit)
- Windows Server 2012 (64-bit)
- Windows Server 2012 R2 (64-bit)
- Windows Server 2008 R2 (64-bit)
The LightDB-A 7 Clients package includes the client and loader programs plus database/role/language commands and the LightDB-A Streaming Server command utilities. Refer to LightDB-A Client and Loader Tools Package for installation and usage details of the LightDB-A 7 Client tools.
Extensions
This table lists the versions of the LightDB-A Extensions that are compatible with this release of LightDB-A Database 6.
| Component | Package Version | Additional Information |
|---|---|---|
| PL/Java | 2.0.4 | Supports Java 8 and 11. |
| Python Data Science Module Package | 2.0.2 | |
| PL/R | 3.0.3 | (CentOS) R 3.3.3 (Ubuntu) You install R 3.5.1+. |
| R Data Science Library Package | 2.0.2 | |
| PL/Container | 2.1.2 | |
| PL/Container Image for R | 2.1.2 | R 3.6.3 |
| PL/Container Images for Python | 2.1.2 | Python 2.7.12 Python 3.7 |
| PL/Container Beta | 3.0.0-beta | |
| PL/Container Beta Image for R | 3.0.0-beta | R 3.4.4 |
| LightDB-AR | 1.1.0 | Supports R 3.6+. |
| MADlib Machine Learning | 1.19, 1.18, 1.17, 1.16 | Support matrix at MADlib FAQ. |
| PostGIS Spatial and Geographic Objects | 2.5.4+pivotal.7.build.1, 2.1.5+pivotal.3.build.3 |
For information about the Oracle Compatibility Functions, see Oracle Compatibility Functions.
These LightDB-A Database extensions are installed with LightDB-A Database
- Fuzzy String Match Extension
- PL/Python Extension
- pgcrypto Extension
Data Connectors
LightDB-A Platform Extension Framework (PXF) - PXF provides access to Hadoop, object store, and SQL external data stores. Refer to Accessing External Data with PXF in the LightDB-A Database Administrator Guide for PXF configuration and usage information.
Note VMware LightDB-A Database versions starting with 6.19.0 no longer bundle a version of PXF. You can install PXF in your LightDB-A cluster by installing the independent distribution of PXF as described in the PXF documentation.
LightDB-A Streaming Server v1.5.3 - The VMware LightDB-A Streaming Server is an ETL tool that provides high speed, parallel data transfer from Informatica, Kafka, Apache NiFi and custom client data sources to a VMware LightDB-A cluster. Refer to the VMware LightDB-A Streaming Server Documentation for more information about this feature.
LightDB-A Streaming Server Kafka integration - The Kafka integration provides high speed, parallel data transfer from a Kafka cluster to a LightDB-A Database cluster for batch and streaming ETL operations. It requires Kafka version 0.11 or newer for exactly-once delivery assurance. Refer to the VMware LightDB-A Streaming Server Documentation for more information about this feature.
LightDB-A Connector for Apache Spark v1.6.2 - The VMware LightDB-A Connector for Apache Spark supports high speed, parallel data transfer between LightDB-A and an Apache Spark cluster using Spark’s Scala API.
LightDB-A Connector for Apache NiFi v1.0.0 - The VMware LightDB-A Connector for Apache NiFi enables you to set up a NiFi dataflow to load record-oriented data from any source into LightDB-A Database.
LightDB-A Informatica Connector v1.0.5 - The VMware LightDB-A Connector for Informatica supports high speed data transfer from an Informatica PowerCenter cluster to a VMware LightDB-A cluster for batch and streaming ETL operations.
Progress DataDirect JDBC Drivers v5.1.4+275, v6.0.0+181 - The Progress DataDirect JDBC drivers are compliant with the Type 4 architecture, but provide advanced features that define them as Type 5 drivers.
Progress DataDirect ODBC Drivers v7.1.6+7.16.389 - The Progress DataDirect ODBC drivers enable third party applications to connect via a common interface to the VMware LightDB-A system.
R2B X-LOG v5.x and v6.x - Real-time data replication solution that achieves high-speed database replication through the use of Redo Log Capturing method.
Note LightDB-A 5.x clients (gpload, gpfdist) are supported with LightDB-A 6.x Server and Informatica PowerCenter and PowerExchange 10.4.
Note VMware LightDB-A 6 does not support the ODBC driver for Cognos Analytics V11.
Connecting to IBM Cognos software with an ODBC driver is not supported. LightDB-A Database supports connecting to IBM Cognos software with the DataDirect JDBC driver for VMware LightDB-A. This driver is available as a download from VMware Tanzu Network.
VMware LightDB-A Text
VMware LightDB-A 6.0 through 6.4 are compatible with VMware LightDB-A Text 3.3.1 through 3.4.1. VMware LightDB-A 6.5 and later are compatible with VMware LightDB-A Text 3.4.2 and later. See the LightDB-A Text documentation for additional compatibility information.
LightDB-A Command Center
VMware LightDB-A 6.15 is compatible only with VMware LightDB-A Command Center 6.4.0 and later. See the LightDB-A Command Center documentation for additional compatibility information.
Hadoop Distributions
LightDB-A Database provides access to HDFS with the LightDB-A Platform Extension Framework (PXF).
PXF can use Cloudera, Hortonworks Data Platform, MapR, and generic Apache Hadoop distributions. PXF bundles all of the JAR files on which it depends, including the following Hadoop libraries:
| PXF Version | Hadoop Version | Hive Server Version | HBase Server Version |
|---|---|---|---|
| 6.x, 5.15.x, 5.14.0, 5.13.0, 5.12.0, 5.11.1, 5.10.1 | 2.x, 3.1+ | 1.x, 2.x, 3.1+ | 1.3.2 |
| 5.8.2 | 2.x | 1.x | 1.3.2 |
| 5.8.1 | 2.x | 1.x | 1.3.2 |
Note If you plan to access JSON format data stored in a Cloudera Hadoop cluster, PXF requires a Cloudera version 5.8 or later Hadoop distribution.
Public Cloud Requirements
Operating System
The operating system parameters for cloud deployments are the same as on-premise with a few modifications. Use the LightDB-A Database Installation Guide for reference. Additional changes are as follows:
Add the following line to sysctl.conf:
net.ipv4.ip_local_reserved_ports=65330
AWS requires loading network drivers and also altering the Amazon Machine Image (AMI) to use the faster networking capabilities. More information on this is provided in the AWS documentation.
Storage
The disk settings for cloud deployments are the same as on-premise with a few modifications. Use the LightDB-A Database Installation Guide for reference. Additional changes are as follows:
- Mount options:
rw,noatime,nobarrier,nodev,inode64> Note Thenobarrieroption is not supported on RHEL 8 or Ubuntu nodes. - Use mq-deadline instead of the deadline scheduler for the R5 series instance type in AWS
- Use a swap disk per VM (32GB size works well)
Security
It is highly encouraged to deactivate SSH password authentication to the virtual machines in the cloud and use SSH keys instead. Using MD5-encrypted passwords for LightDB-A Database is also a good practice.
Amazon Web Services (AWS)
Virtual Machine Type
AWS provides a wide variety of virtual machine types and sizes to address virtually every use case. Testing in AWS has found that the optimal instance types for LightDB-A are “Memory Optimized”. These provide the ideal balance of Price, Memory, Network, and Storage throughput, and Compute capabilities.
Price, Memory, and number of cores typically increase in a linear fashion, but the network speed and disk throughput limits do not. You may be tempted to use the largest instance type to get the highest network and disk speed possible per VM, but better overall performance for the same spend on compute resources can be obtained by using more VMs that are smaller in size.
Compute
AWS uses Hyperthreading when reporting the number of vCPUs, therefore 2 vCPUs equates to 1 Core. The processor types are frequently getting faster so using the latest instance type will be not only faster, but usually less expensive. For example, the R5 series provides faster cores at a lower cost compared to R4.
Memory
This variable is pretty simple. LightDB-A needs at least 8GB of RAM per segment process to work optimally. More RAM per segment helps with concurrency and also helps hide disk performance deficiencies.
Network
AWS provides 25Gbit network performance on the largest instance types, but the network is typically not the bottleneck in AWS. The “up to 10Gbit” network is sufficient in AWS.
Installing network drivers in the VM is also required in AWS, and depends on the instance type. Some instance types use an Intel driver while others use an Amazon ENA driver. Loading the driver requires modifying the machine image (AMI) to take advantage of the driver.
Storage
Elastic Block Storage (EBS)
The AWS default disk type is General Performance (GP2) which is ideal for IOP dependent applications. GP2 uses SSD disks and relative to other disk types in AWS, is expensive. The operating system and swap volumes are ideal for GP2 disks because of the size and higher random I/O needs.
Throughput Optimized Disks (ST1) are a disk type designed for high throughput needs such as LightDB-A. These disks are based on HDD rather than SSD, and are less expensive than GP2. Use this disk type for the optimal performance of loading and querying data in AWS.
Cold Storage (SC1) provides the best value for EBS storage in AWS. Using multiple 2TB or larger disks provides enough disk throughput to reach the throughput limit of many different instance types. Therefore, it is possible to reach the throughput limit of a VM by using SC1 disks.
EBS storage is durable so data is not lost when a virtual machine is stopped. EBS also provides infrastructure snapshot capabilities that can be used to create volume backups. These snapshots can be copied to different regions to provide a disaster recovery solution. The LightDB-A Cloud utility gpsnap, available in the AWS Cloud Marketplace, automates backup, restore, delete, and copy functions using EBS snapshots.
Storage can be grown in AWS with “gpgrow”. This tool is included with the LightDB-A on AWS deployment and allows you to grow the storage independently of compute. This is an online operation in AWS too.
Ephemeral
Ephemeral Storage is directly attached to VMs, but has many drawbacks: - Data loss when stopping a VM with ephemeral storage - Encryption is not supported - No Snapshots - Same speed can be achieved with EBS storage - Not recommended
AWS Recommendations
Coordinator
| Instance Type | Memory | vCPUs | Data Disks |
|---|---|---|---|
| r5.xlarge | 32 | 4 | 1 |
| r5.2xlarge | 64 | 8 | 1 |
| r5.4xlarge | 128 | 16 | 1 |
Segments
| Instance Type | Memory | vCPUs | Data Disks |
|---|---|---|---|
| r5.4xlarge | 128 | 16 | 3 |
Performance testing has indicated that the Coordinator node can be deployed on the smallest r5.xlarge instance type to save money without a measurable difference in performance. Testing was performed using the TPC-DS benchmark.
The Segment instances run optimally on the r5.4xlarge instance type. This provides the highest performance given the cost of the AWS resources.
Google Compute Platform (GCP)
Virtual Machine Type
The two most common instance types in GCP are “Standard” or “HighMem” instance types. The only difference is the ratio of Memory to Cores. Each offer 1 to 64 vCPUs per VM.
Compute
Like AWS, GCP uses Hyperthreading, so 2 vCPUs equates to 1 Core. The CPU clock speed is determined by the region in which you deploy.
Memory
Instance type n1-standard-8 has 8 vCPUs with 30GB of RAM while n1-highmem-8 also has 8 vCPUs with 52GB of RAM. There is also a HighCPU instance type that generally isn’t ideal for LightDB-A. Like AWS and Azure, the machines with more vCPUs will have more RAM.
Network
GCP network speeds are dependent on the instance type but the maximum network performance is possible (10Gbit) with a virtual machine as small as only 8 vCPUs.
Storage
Standard (HDD) and SSD disks are available in GCP. SSD is slightly faster in terms of throughput but comes at a premium. The size of the disk does not impact performance.
The biggest obstacle to maximizing storage performance is the throughput limit placed on every virtual machine. Unlike AWS and Azure, the storage throughput limit is relatively low, consistent across all instance types, and only a single disk is needed to reach the VM limit.
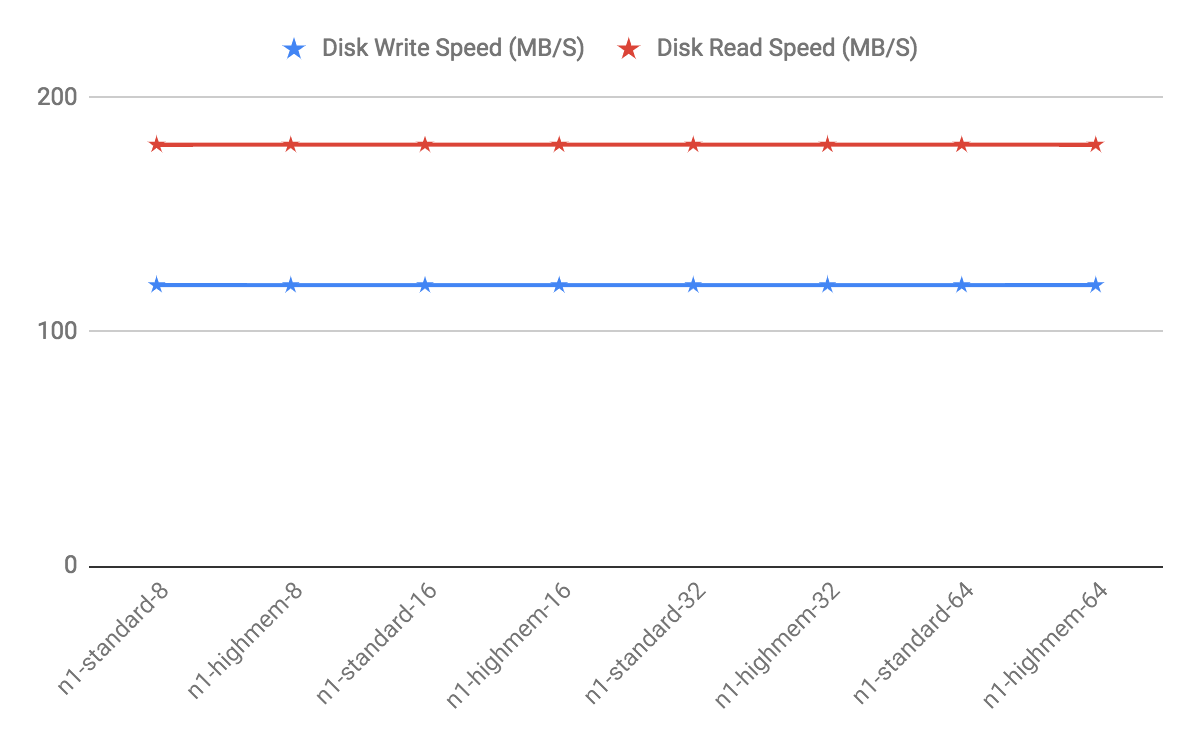
GCP Recommendations
Testing has revealed that while using the same number of vCPUs, a cluster using a large instance type like n1-highmem-64 (64 vCPUs) will have lower performance than a cluster using more of the smaller instance types like n1-highmem-8 (8 vCPUs). In general, use 8x more nodes in GCP than you would in another environment like AWS while using the 8 vCPU instance types.
The HighMem instance type is slightly faster for higher concurrency. Furthermore, SSD disks are slightly faster also but come at a cost.
Coordinator and Segment Instances
| Instance Type | Memory | vCPUs | Data Disks |
|---|---|---|---|
| n1-standard-8 | 30 | 8 | 1 |
| n1-highmem-8 | 52 | 8 | 1 |
Azure
Note On the Azure platform, in addition to bandwidth, the number of network connections present on a VM at any given moment can affect the VM’s network performance. The Azure networking stack maintains the state for each direction of a TCP/UDP connection in a data structures called a flow. A typical TCP/UDP connection will have 2 flows created: one for the inbound direction and another for the outbound direction. The number of network flows on Azure is limited to an upper bound. See Virtual machine network bandwidth in the Azure documentation for more details. In practice this can present scalability challenges for workloads based on the number of concurrent queries, and on the complexity of those queries. Always test your workload on Azure to validate that you are within the Azure limits, and be advised that if your workload increases you may hit Azure flow count boundaries at which point your workload may fail. VMware recommends using the UDP interconnect, and not the TCP interconnect, when using Azure. A connection pooler and resource group settings can also be used to help keep flow counts at a lower level.
Virtual Machine Type
Each VM type has limits on disk throughput so picking a VM that doesn’t have a limit that is too low is essential. Most of Azure is designed for OLTP or Application workloads, which limits the choices for databases like LightDB-A where throughput is more important. Disk type also plays a part in the throughput cap, so that needs to be considered too.
Compute
Most instance types in Azure have hyperthreading enabled, which means 1 vCPU equates to 2 cores. However, not all instance types have this feature, so for these others, 1 vCPU equates to 1 core.
The High Performance Compute (HPC) instance types have the fastest cores in Azure.
Memory
In general, the larger the virtual machine type, the more memory the VM will have.
Network
The Accelerated Networking option offloads CPU cycles for networking to “FPGA-based SmartNICs”. Virtual machine types either support this or do not, but most do support it. Testing of LightDB-A hasn’t shown much difference and this is probably because of Azure’s preference for TCP over UDP. Despite this, UDPIFC interconnect is the ideal protocol to use in Azure.
There is an undocumented process in Azure that periodically runs on the host machines on UDP port 65330. When a query runs using UDP port 65330 and this undocumented process runs, the query will fail after one hour with an interconnect timeout error. This is fixed by reserving port 65330 so that LightDB-A doesn’t use it.
Storage
Storage in Azure is either Premium (SSD) or Regular Storage (HDD). The available sizes are the same and max out at 4TB. Instance types either do or do not support Premium but, interestingly, the instance types that do support Premium storage, have a lower throughput limit. For example:
- Standard_E32s_v3 has a limit of 768 MB/s.
- Standard_E32_v3 was tested with
gpcheckperfto have 1424 write and 1557 read MB/s performance.
To get the maximum throughput from a VM in Azure, you have to use multiple disks. For larger instance types, you have to use upwards of 32 disks to reach the limit of a VM. Unfortunately, the memory and CPU constraints on these machines means that you have to run fewer segments than you have disks, so you have to use software RAID to utilize all of these disks. Performance takes a hit with software RAID, too, so you have to try multiple configurations to optimize.
The size of the disk also impacts performance, but not by much.
Software RAID not only is a little bit slower, but it also requires umount to take a snapshot. This greatly lengthens the time it takes to take a snapshot backup.
Disks use the same network as the VMs so you start running into the Azure limits in bigger clusters when using big virtual machines with 32 disks on each one. The overall throughput drops as you hit this limit and is most noticeable during concurrency testing.
Azure Recommendations
The best instance type to use in Azure is “Standard_H8” which is one of the High Performance Compute instance types. This instance series is the only one utilizing InfiniBand, but this does not include IP traffic. Because this instance type is n0t available in all regions, the “Standard_D13_v2” is also available.
Coordinator
| Instance Type | Memory | vCPUs | Data Disks |
|---|---|---|---|
| D13_v2 | 56 | 8 | 1 |
| H8 | 56 | 8 | 1 |
Segments
| Instance Type | Memory | vCPUs | Data Disks |
|---|---|---|---|
| D13_v2 | 56 | 8 | 2 |
| H8 | 56 | 8 | 2 |